7. Statistický soubor s jedním argumentem
Předchozí kapitoly byly věnovány pravděpodobnosti a tomu, co s tímto pojmem souvisí. Nyní znalosti z počtu pravděpodobnosti aplikujeme ve statistice.
Pojmy z předchozích kapitol.
Cílem této kapitoly je zavést a objasnit pojem statistika, seznámit se základní statistickou terminologií a definovat charakteristiky statistického souboru s jedním argumentem.
7.1. Úvod do statistiky
Několik citátů na úvod:
Nevěřím jiné statistice, než té, kterou jsem osobně zfalšoval.
Winston Churchill
Statistika je obzvláště rafinovaná forma lži.
???
S pomocí statistiky je jednoduché lhát. Bez ní je ale těžké říci pravdu.
Andrejs Dunkels
Už z těchto vět je patrné, že statistika měla a má poněkud pošramocenou pověst vědy, která má často vytvářet pouze jakousi iluzi pravdy a jejíž přímým úkolem je někdy skutečnost úmyslně mást (na obranu statistiky i W. Churchilla nutno poznamenat, že v případě prvního citátu se pravděpodobně jedná o podvrh, fámu o tomto údajném Churchillově výroku rozšířil německý ministr propagandy Joseph Goebbels).
Jak jednoduché je ze správných statistických údajů vyvodit nesmyslné závěry, můžeme dokumentovat na následujícím příkladě: Je statisticky dokázáno, že každé čtvrté dítě, které se narodí, je Číňan.
Znamená to však něco při plánování počtu dětí pro průměrnou českou rodinu? Většina čtenářů asi tuší, že nikoliv. Jsme však schopni takový rozpor vždy odhalit?
Abychom se tedy vyvarovali nesprávných úsudků vyplývajících z neznalosti, je vhodné se seznámit se základy matematické statistiky a s jejími možnostmi.
Nejčastější aplikace počtu pravděpodobnosti směřují do oblasti statistiky. Její nejrozšířenější část, tzv. matematická statistika, se zabývá metodami získávání, zpracování a vyhodnocování hromadných dat (tzn. údajů o vlastnostech velkého počtu jedinců - osob, věcí či jevů).
Podle použitých metod práce dělíme matematickou statistiku na
- deskriptivní, popisnou statistiku - zabývá se efektivním získáváním ukazatelů, které poskytují obraz zkoumaného jevu;
- statistickou indukci (matematickou statistiku v užším smyslu) - řeší problémy zobecňování výsledků získaných popisem statistického souboru.
Množinu všech předmětů pozorování ( osob, věcí, jevů apod.)
shromážděných na základě toho, že mají společné vlastnosti, nazýváme
statistickým souborem. Jednotlivé prvky této množiny se nazývají prvky
(elementy) statistického souboru nebo též statistické jednotky. Počet všech
prvků statistického souboru se nazývá rozsah souboru N.
Soubor, který je předmětem zkoumání, se nazývá základní soubor. Často
nelze nebo není účelné provést zkoumání všech statistických jednotek tohoto
základního souboru. Základní soubor pak zkoumáme pomocí statistických
jednotek, které z něj byly určitým způsobem vybrány a které tvoří takzvaný
výběrový soubor.
Poznámka
Například: Při zjišťování výšky studentů ve studijní skupině je statistickým souborem množina
studentů dané skupiny. Jejich společnou vlastností je, že jsou studenty například studijní skupiny JB007 Vysoké školy báňské,
a že budeme zkoumat jejich výšku. Statistickou
jednotkou je student dané skupiny. Rozsahem souboru je počet
studentů dané skupiny, například 21. Statistickým souborem může být také množina
všech studentů této školy.
Vlastnosti statistických souborů, které jsou předmětem statistického
zkoumání, sleduje statistika prostřednictvím vlastností statistických jednotek
daného souboru, které postihuje statistickými znaky.
Statistický znak je vyjádřením určité vlastnosti statistických jednotek
(prvků množin) sledovaného statistického souboru; slouží k charakterizování
sledovaného hromadného jevu-vlastnosti daného statistického souboru.
Znak (argument) souboru se zpravidla značí x. Jednotlivé údaje znaku se
nazývají hodnoty znaku, značí se x1, x2, xN, kde N je rozsah souboru.
Poznámka
Například: Například při určování výšky studentů dané studijní skupiny je statistickým znakem
výška studentů, hodnotou znaku je číselně vyjádřená příslušná výška studenta, např.182 cm.
Hodnoty znaku mohou být vyjádřeny buď čísly nebo jiným způsobem
(zpravidla slovním popisem). V prvním případě mluvíme o znacích
kvantitativních, např. tělesná výška, tělesná hmotnost, počet obyvatel měst, atp..
V druhém případě mluvíme o znacích kvalitativních, které se mohou vyskytovat
ve dvou druzích (znaky alternativní, např. muž-žena, voják-nevoják, prospěl-neprospěl)
nebo ve více druzích (např. povolání, národnost, náboženství, atp.).
Další pojmy
Když
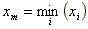
a
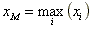
, pak interval
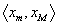
je
variační obor argumentu
X.
Hodnota
R = xM - xm je
variační rozpětí argumentu X.
Jestliže se hodnota
xi vyskytne v souboru
fi-krát,
je
fi absolutní četnost hodnoty xi.
Hodnoty
xi seřazené podle velikosti a jejich absolutní četnosti
fi tvoří
variační řadu (statistickou řadu).
Hodnota
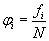
(
N je rozsah souboru) je
relativní četnost hodnoty
xi.
Hodnota
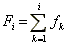
je
kumulativní četnost do
xi.
Hodnota
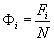
je
relativní kumulativní četnost do
xi.
Řešené úlohy
Příklad 7.2.1.
Určete relativní, kumulativní a relativní kumulativní četnosti variační řady
| xi |
0 |
1 |
2 |
3 |
4 |
| fi |
7 |
44 |
56 |
30 |
12 |
Řešení:
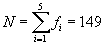
Všechny četnosti vypočteme z výše uvedených vzorců:
| xi |
0 |
1 |
2 |
3 |
4 |
S |
| fi |
7 |
44 |
56 |
30 |
12 |
149 |
| fi |
0,047 |
0,295 |
0,376 |
0,201 |
0,081 |
1 |
| Fi |
7 |
51 |
107 |
137 |
149 |
|
| Fi |
0,047 |
0,342 |
0,718 |
0,919 |
1 |
|
7.3. Charakteristiky statistického souboru s jedním argumentem
Charakteristiky statistických souborů se definují analogicky jako charakteristiky náhodné proměnné X, jíž u statistických souborů je uvažovaný argument. Úlohu pravděpodobnosti hrají zde relativní četnosti (ve shodě se statistickou definicí pravděpodobnosti) a funkce φ(x) a Φ(x) lze považovat za empirické pravděpodobnostní funkce variační řady s analogickými vlastnostmi, jaké mají funkce rozložení pravděpodobnosti náhodné veličiny.
Mezi nejdůležitější charakteristiky patří charakteristiky polohy, střední hodnota, modus, medián a kvantily.
Definice 7.3.1.
- Empirická střední hodnota je
-
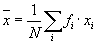 .
.
- Modus statistického souboru Mo(x)
- je ta hodnota argumentu X,
která má největší absolutní četnost.
- Medián statistického souboru Me(x)
- je ta hodnota argumentu X,
která rozděluje soubor uspořádaný na dvě části o stejném počtu prvků.
Má-li soubor sudý počet prvků, považuje se za medián průměrná hodnota prostředních dvou.
- Empirický p-kvantil
- je taková hodnota xp, pro kterou platí,
že 100p procent prvků souboru je nanejvýš rovných xp.
Nejčastěji používanými kvantily jsou kvartily, decily a percentily. Definujte je. A co je z hlediska kvantilů vlastně medián?
Druhou skupinu charakteristik jsou charakteristiky variability, empirický rozptyl (disperze), směrodatná (standardní) odchylka, průměrná odchylka a variační koeficient. Většina z nich je přímou analogií příslušných teoretických ukazatelů.
Definice 7.3.2.
- Empirický rozptyl (empirická disperze) je dán vztahem
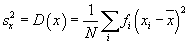
- Empirická směrodatná (standardní) odchylka je
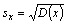
- Průměrná odchylka je určena vztahem
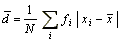
- Variační koeficient je dán vztahem
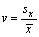 (často se udává v procentech).
(často se udává v procentech).
Poznámky
Základní vlastnosti směrodatné odchylky:
- směrodatná odchylka měří rozptýlenost kolem průměru
- s = 0 pouze v případech, kdy se všechna data rovnají stejné hodnotě, jinak s > 0
- stejně jako průměr je i směrodatná odchylka silně ovlivněna extrémními hodnotami, i jedna nebo dvě odlehlé hodnoty ji silně zvětšují
- je-li rozdělení dat silně zešikmené (zjistíme pomocí koeficientu šikmosti), směrodatná odchylka neposkytuje dobrou informaci o rozptýlenosti dat - v těchto případech používáme kvantilové charakteristiky - viz. dále
Variační koeficient používáme, jestliže chceme posoudit relativní velikost rozptýlenosti dat vzhledem k průměru. Počítáme ho, když chceme porovnat rozptýlenost dat skupin měření stejné proměnné s různým průměrem, nebo v případech, kdy se mění velikost směrodatné odchylky tak, že je přímo závislá na úrovni měřené proměnné.
Důležitou roli opět i ve statistice hrají momentové charakteristiky. Uveďme jen jejich definice značené latinskými ekvivalenty řeckých označení z počtu pravděpodobnosti.
Definice 7.3.3.
- Počáteční empirický moment k-tého řádu

- Centrální empirický moment k-tého řádu
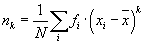
- Normovaný empirický moment k-tého řádu
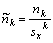
Samozřejmě platí analogické vztahy pro výpočty momentů centrálních z počátečních:
n2 = m2 - m12
n3 = m3 - 3m2m1 + 2m13
n4 = m4 - 4m3m1 + 6m2m12 - 3m14
Normované momenty použijeme i tady jako ukazatele šikmosti a špičatosti:
Definice 7.3.4.
- Empirický koeficient šikmosti
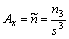
- Empirický exces
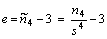
Řešené úlohy
Příklad 7.3.1.
Vypočtěte empirické charakteristiky, modus a kvartily variační řady:
| xi |
0 |
1 |
2 |
3 |
4 |
| fi |
7 |
44 |
51 |
30 |
12 |
Řešení:
Ukážeme dva způsoby výpočtu v Excelu:
Nejdříve charakteristiky vypočteme přesně podle vzorců, které jsme uvedli:
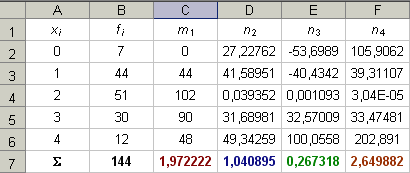
Z tabulka snadno dopočteme číselné charakteristiky:
Střední hodnota:
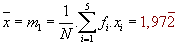
Rozptyl:
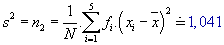
Směrodatná odchylka:
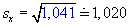
Koeficient šikmosti:
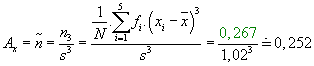
Exces:
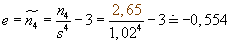
Modus: největší absolutní četnost má hodnota 2, takže:
Mo(
x) = 2
Při výpočtu kvartilů určíme nejprve jejich pořadí podle vzorce:
zp =
N.p + 0,5, tedy:
z0,25 = 144.0,25 + 0,5 = 36,5
z0,5 = 144.0,5 + 0,5 = 72,5
z0,75 = 144.0,75 + 0,5 = 108,5
Z výpočtu pořadí vidíme, že 1.kvartil se vypočte jako aritmetický průměr hodnot 36 a 37 prvku - z tabulky je zřejmé, že obě jsou rovny 1, tzn.
x0,25 = 1, obdobně
x0,5 = 2 (medián)
x0,75 = 3
Druhá možnost je použití předdefinovaných funkcí v Excelu:
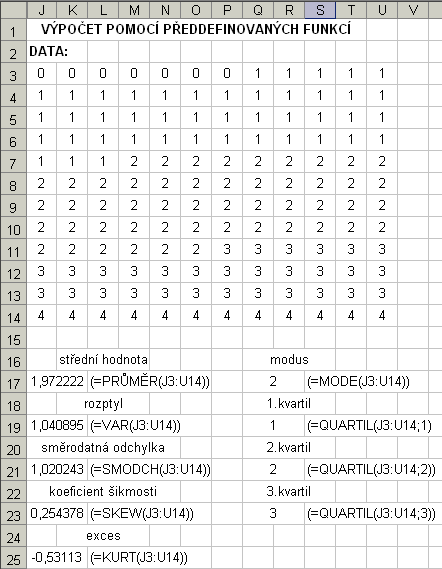
Pro pokročilé uživatele Excelu bude možná nejvhodnější třetí možnost, jak vyřešit tuto úlohu. Použijeme doplňkový nástroj Excelu, který se nazývá
Analýza dat.
Pokud v menu Excelu v nabídce
Nástroje nenajdete tento nástroj, je nutné ho doinstalovat. Tento úkon je velmi jednoduchý. V nabídce
Nástroje klepněte na příkaz
Doplňky.
V seznamu
Doplňky k dispozici zaškrtněte políčko u položky
Analytické nástroje a klepněte na tlačítko
OK. Po instalaci by mělo být možné doplněk spustit z nabídky
Nástroje.
Chceme-li vypočítat příslušné charakteristiky, data umístíme do jednoho sloupce (řádku) a v dialogovém okně
Analýza dat klepneme na analytický nástroj
Popisná statistika a nastavíme požadované možnosti analýzy.
Výstup pak v našem příkladě vypadá takto:

Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
7.4. Zpracování rozsáhlého statistického souboru
Obsahuje-li statistický soubor velký počet různých hodnot argumentu X, sdružujeme hodnoty argumentu do intervalů zvaných třídy. Obvykle volíme konstantní šířku třídy.
Hranice tříd je nutno volit tak, aby každý prvek statistického souboru bylo možné zařadit právě do jedné třídy.
Počet tříd volíme podle účelu zkoumání, obvykle 5-20 tříd. Přesné pravidlo pro výpočet počtu tříd neexistuje. Uvedeme alespoň některé doporučované možnosti:
-
pro šířku třídy h by mělo přibližně platit
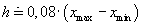 ,
,
- počet tříd n by měl být
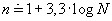 nebo
nebo
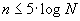 nebo
nebo
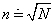 ,
,
- pro
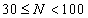 volíme 7-10 tříd,
volíme 7-10 tříd,
pro 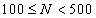 volíme nejvýše 15 tříd,
volíme nejvýše 15 tříd,
pro 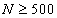 volíme nejvýše 20 tříd.
volíme nejvýše 20 tříd.
Při zpracování statistického souboru nahradíme všechny hodnoty v dané třídě jedinou hodnotou, tzv. třídním znakem, kterým je
aritmetický průměr obou mezí třídy. Třídní znak zastupuje všechny hodnoty, které do této třídy patří.
Počet hodnot ve třídě je třídní četnost.
Po rozdělení souboru do tříd už nepočítáme s jednotlivými hodnotami, ale s třídami, třídními znaky a třídními četnostmi.
Rozdělením variačního oboru na třídy a shrnutím všech hodnot argumentu v každé třídě do třídního znaku se dopouštíme při výpočtu centrálních momentů systematických chyb. Anglický statistik W. F. Shepard odvodil v r. 1897 korekce, jimiž lze tyto chyby korigovat.
Značí-li h šířku tříd, jsou opravené momenty dány vzorci:
- Shepardovy korekce
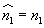

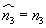 (liché momenty se neopravují)
(liché momenty se neopravují)
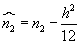

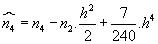
- Modus se u rozsáhlého statistického souboru, který je rozdělen do tříd, vypočte interpolací:
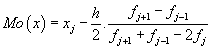
xj ... střed j-té třídy s největší absolutní četností fj
h ... šířka třídy
- Kvantily se v tomto případě určí opět interpolací:
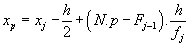
j ... pořadí třídy, do níž je zařazen (N.p)-tý prvek uspořádaného souboru
xj ... střed j-té třídy
Fj - 1 ... kumulativní absolutní četnost (j - 1)-vé třídy
fj ... absolutní četnost j-té třídy
Řešené úlohy
Příklad 7.4.1.
Na jednom nejmenovaném pracovišti byly při zjišťování IQ naměřeny následující hodnoty:
68, 71, 71, 78, 82, 82, 87, 91, 92, 92, 95, 97, 102, 102, 102, 103, 105, 105, 109, 110,
111, 111, 111, 112, 112, 114, 114, 114, 115, 116, 118, 119, 121, 122, 122, 124, 126, 131, 133, 137.
Rozdělte tyto hodnoty do osmi tříd a určete empirické charakteristiky, modus a kvartily.
Řešení:
xmax -
xmin = 137 - 68 = 69
Vypočteme šířku třídy:
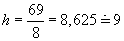
Když ale nyní vynásobím 9.8 = 72, to je o tři více než původně vypočtené variační rozpětí.
Dolní hranici 1.třídy proto zvolím o 1,5 menší, než je
xmin, tedy 66,5.
K výpočtu empirických charakteristik je vhodné použít např. Excel - viz. tabulka:
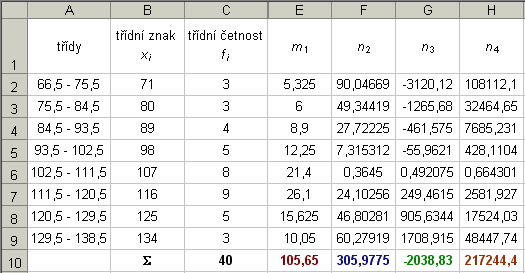
Z hodnot v tabulce pak snadno vypočteme hledané charakteristiky:
Empirická střední hodnota:
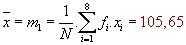
Empirická disperze:
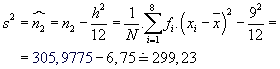
Empirická směrodatná odchylka:
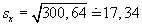
Empirický koeficient šikmosti:
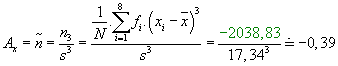
Empirický exces:
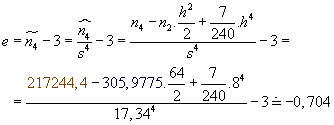
Modus:
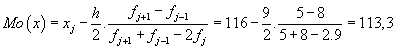
K výpočtu kvartilů budeme potřebovat ještě tabulku kumulativních třídních četností
Fi:
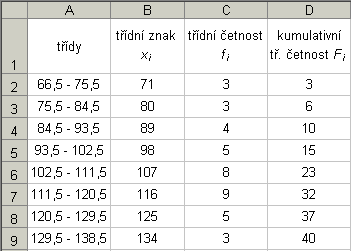
1.kvartil:
N.p = 40.0,25 = 10
10-tý prvek leží ve třetí třídě, tudíž
j = 3
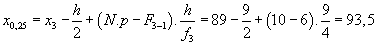
2.kvartil (medián):
N.p = 40.0,5 = 20
20-tý prvek leží v páté třídě, tudíž
j = 5
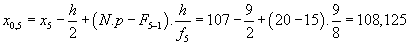
3.kvartil:
N.p = 40.0,75 = 30
30-tý prvek leží v šesté třídě, tudíž
j = 6
Pro srovnání ještě uvedeme hodnoty charakteristik, vypočtené (opět v Excelu) bez rozdělení do tříd:
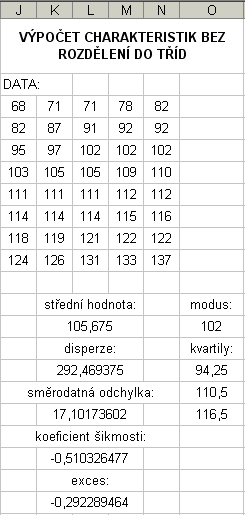
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Poznámka
Způsob zpracování statistických dat závisí na tom, jak jsou vstupní data zadána (netříděný soubor individuálních hodnot, tříděný soubor - četnostní tabulka), jak velký je rozsah souboru, zda je ke zpracování možno použít výpočetní techniky. Tvar výpočetních tabulek, které je třeba při výpočtech vytvořit, je dost individuální. I při "ručním" zpracování dat je však možno doporučit metody práce, jaké jsou běžné v tabulkových kalkulátorech, např. v excelu.
Pro práci se statickými soubory si zopakujte základní výpočetní postupy v excelu. Vyhledejte v nabídce vestavěných funkcí, které z nich odpovídají funkcím, které jsme uváděli jako charakteristiky statistického souboru (kategorie statistických funkcí, ale k některým triviálním výpočtům použijeme i některé funkce matematické).
Ještě jeden citát na závěr:
Statistik je ten, kdo s hlavou v rozpálené troubě a s nohama v nádobě s ledem na dotaz, jak se cítí, odpoví: "V průměru se cítím dobře."
anonym