12. Testování statistických hypotéz
Navážeme na předchozí kapitolu 11 a vysvětlíme některé statistické testy.
Pojmy z předchozích kapitol.
Cílem této kapitoly je vysvětlit postup při testování statistických hypotéz a seznámit s některými konkrétními statistickými testy.
12.1. Statistické hypotézy - úvod
Od statistického šetření neočekáváme pouze elementární informaci o velikosti některých statistických ukazatelů. Používáme je i
k ověřování našich očekávání o výsledcích nějakého procesu, k posuzování významnosti změn, které byly způsobeny změnou
technologie, apod. Ukážeme, že ač formulace úloh toho typu se liší od formulace úlohy o odhadech parametrů, jde zpravidla vždy o řešení
inverzní úlohy o intervalovém odhadu. Zaveďme si však napřed příslušnou terminologii.
Definice 12.1.1.
- Statistická hypotéza
- je tvrzení, které se týká neznámé vlastnosti rozdělení pravděpodobnosti náhodné proměnné (i vícerozměrné) nebo
jejích parametrů.
Hypotéza, jejíž platnost ověřujeme, se nazývá nulová hypotéza H0.
Proti nulové hypotéze stavíme alternativní hypotézu H1. Ta může být buď oboustranná nebo jednostranná.
Pak i testy jsou buď oboustranné nebo jednostranné.
Hypotézy se mohu týkat pouze neznámých číselných parametrů rozložení náhodné veličiny, pak jde o testy parametrické.
Ostatní typy jsou testy neparametrické.
- Statistické testy
- jsou postupy, jimiž prověřujeme platnost nulové hypotézy. Na základě nich pak hypotézu buď přijmeme nebo odmítneme.
- Testovací kritérium
- je náhodná veličina závislá na náhodném výběru (též nazývaná statistika) mající vztah k nulové hypotéze.
Jednostranné a oboustranné testy se od sebe rozlišují z hlediska alternativní hypotézy, kterou stavíme proti prověřované nulové hypotéze a
která může být dvojího druhu, jak plyne z tohoto příkladu:
Nechť nulová hypotéza předpokládá, že A = B. V případě, že tuto hypotézu zamítneme, je buď A ≠ B,
nebo A > B (resp. A < B).
a) V prvém případě (A ≠ B) nebereme zřetel na znaménko rozdílu A - B, takže může být
buďA - B < 0 nebo A - B > 0. V těchto případech používáme oboustranný test.
b) V druhém případě, kdy proti hypotéze A = B klademe možnost A > B (resp. A < B),
používáme jednostranných testů.
Pro
kritické hodnoty testovacího kritéria
ap,
bp platí:
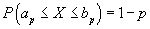
.
Tyto hodnoty oddělují
interval prakticky možných hodnot (interval spolehlivosti, konfidenční interval) <
ap,
bp> od
kritických intervalů, v nichž se hodnoty veličiny
X vyskytují s pravděpodobností
p, které říkáme hladina významnosti.
Nejčastěji volíme
p = 0,01 nebo
p = 0,05.
Pro oboustranné odhady volíme:
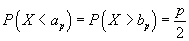
,
pro jednostranné buď
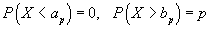
nebo
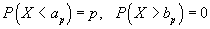
.
Porovnání hodnoty testovacího kritéria s jeho kritickými hodnotami slouží k rozhodnutí o výsledku testu.
Musíme si uvědomit, že nemůžeme mluvit o
dokazování správnosti či nesprávnosti zvolené hypotézy - to není v možnostech statistické indukce. Závěr testu pouze rozhodne mezi dvěmi možnostmi:
- hypotézu přijímáme (zamítáme alternativní hypotézu), leží-li pozorovaná hodnota testovacího kritéria v intervalu prakticky možných hodnot.
Znamená to, že rozdíl mezi pozorovanou a teoretickou hodnotou testovacího kritéria je vysvětlitelný na dané hladině významnosti p náhodností výběru.
- hypotézu zamítáme (přijímáme alternativní hypotézu), leží-li pozorovaná hodnota testovacího kritéria v kritickém oboru.
Rozdíly považujeme za statisticky významné na zvolené hladině významnosti p, tzn., že se nedají vysvětlit pouze náhodností výběru.
Příklady otázek, na které se dá odpovídat pomocí výsledků příslušných statistických testů:
- Má základní soubor (ZS) předpokládanou střední hodnotu?
- Mají dva soubory stejnou disperzi?
- Můžeme předpokládat, že dva výběry pocházejí z téhož ZS?
- Má ZS předpokládané rozdělení?
atd.
Těmito slovy jistě nebudou technici formulovat své otázky v konkrétním průmyslovém podniku. Bude je ale např. zajímat,
zda
- bylo dodáno uhlí deklarované kvality
- dva měřící přístroje pracují stejně přesně
- se nezměnily provozní podmínky ovlivňující výrobu (např. seřízení obráběcích strojů)
- produkce zmetků v jednotlivých hodinách je rovnoměrná
(Pokuste se popsat konkrétní provozní realizace výše uvedených situací.)
Ve shodě s běžnými zvyklostmi definujme:
Definice 12.1.2.
- Nechť b je pozorovaná, kdežto β teoretická hodnota statistiky B a nechť
<ap, bp> je interval prakticky možných hodnot veličiny B na 100p% hladině
významnosti.
- Pak říkáme, že rozdíl b - β je
1. náhodně vysvětlitelný, když 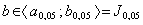 ;
;
2. statisticky významný, když 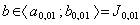 ;
;
3. slabě statisticky významný, když 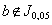 , ale
, ale
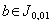 .
.
12.1.1. Kroky při testování hypotézy
- Formulace výzkumné otázky ve formě nulové a alternativní statistické hypotézy
- Zvolení přijatelné úrovně chyby rozhodování (volba hladiny významnosti p)
- Volba testovacího kritéria
- Výpočet hodnoty testovacího kritéria
- Určení kritických hodnot testovacího kritéria
- Doporučení (přijmutí nebo zamítnutí nulové hypotézy H0)
Poznámky
- Hladina významnosti je pravděpodobnost, že se zamítne nulová hypotéza, ačkoliv ona platí. Pochopitelně se tato hodnota volí velmi malá, jak již bylo řečeno, nejčastěji 0,05 nebo 0,01.
- Jestliže test neindikuje zamítnutí nulové hypotézy H0, je nesprávné přijmout nulovou hypotézu jako definitivně pravdivou.
Správně můžeme pouze prohlásit, že není dostatek dokladů pro zamítnutí nulové hypotézy.
- Netvrďme, že data ukazují, že teorie platí/neplatí. Správnější je říct, že data podporují nebo nepodporují rozhodnutí o zamítnutí platnosti nulové hypotézy.
12.1.2. Test jako rozhodování
Při testování hypotéz mohou nastat čtyři možnosti, které popisuje následující tabulka:
|
Závěr testu |
| H0 platí |
H0 neplatí |
| Skutečnost |
H0 platí |
správný |
chyba I. druhu |
| H0 neplatí |
chyba II. druhu |
správný |
Existují tedy dvě možnosti chyby:
- chyba I. druhu - nulová hypotéza platí, ale zamítne se;
- chyba II. druhu - nulová hypotéza neplatí, ale přijme se.
Přirovnáme-li tuto situaci k medicínskému testování, pak chyba I. druhu znamená falešně pozitivní výsledek (pacient je zdráv, ale testování ukazuje na nemoc),
chyba II. druhu odpovídá falešně negativnímu výsledku (pacient je nemocný, ale test to neodhalí).
Pravděpodobnost chyby I. druhu je podmíněná pravděpodobnost, že zamítneme nulovou hypotézu za předpokladu, že platí - označujeme
p - viz. výše.
Pravděpodobnost chyby II. druhu je podmíněná pravděpodobnost, že nezamítneme nulovou hypotézu za předpokladu, že neplatí, označujeme
p0:
P(chyba I. druhu | H0 platí) = p
P(chyba II. druhu | H1 neplatí) = p0
Konvenční hodnoty pro
p0 jsou 0,2 nebo 0,1.
Někdy můžeme také mluvit o opačných jevech k chybě I. a II. druhu, tzn. o podmíněné pravděpodobnosti, že neuděláme chybu I. druhu (spolehlivost testu) nebo že neuděláme chybu II. druhu.
Síla testu odpovídá hodnotě (1 -
p0). Jedná se tedy o podmíněnou pravděpodobnost, že správně odhalíme testem neplatnost nulové hypotézy:
P(neuděláme chybu I. druhu | H0 platí) = 1 - p = ”spolehlivost“
P(neuděláme chybu II. druhu | H1 neplatí) = 1 - p0 = ”síla testu“
Cílem při testování nulové hypotézy je omezit úrovně pravděpodobnosti chyb I. a II.druhu. Jinými slovy - usilujeme o maximalizaci spolehlivosti a síly testu.
Řešené úlohy
Příklad 12.1.1.
Testování přiblížíme pomocí analogie se soudním procesem. Má padnout rozhodnutí, zda obžalovaný spáchal či nespáchal zločin.
Řešení:
Soudní systém se řídí zásadou, že obžalovaný je nevinen, dokud se nepodaří prokázat opak. Formulace hypotéz má tedy tuto podobu:
H0: Obžalovaný je nevinen.
H1: Obžalovaný je vinen.
Různé možnosti vztahu mezi pravdou a rozhodnutím soudu vidíme v tabulce:
|
Závěr soudu |
| Obžalovaný je nevinen |
Obžalovaný je vinen |
| Skutečnost |
Obžalovaný je nevinen |
správný |
chyba I. druhu |
| Obžalovaný je vinen |
chyba II. druhu |
správný |
Uvědomme si, že chyba I. druhu má pro jedince fatální následky. Proto její možnost eliminujeme na nejmenší možnou míru.
Soud musí jasně prokázat vinu obžalovaného. Jeho rozhodnutí také podléhají přezkoumání vyšších instancí. Odpovídá to volbě velmi malé hladiny významnosti.
V mnoha jiných případech však nevíme zcela přesně, která chyba je pro nás důležitější.
V další části uvedeme některé důležité statistické testy:
12.2. Hypotézy o rozptylu
12.2.1. Test významnosti rozdílu dvou rozptylů (F-test)
Předpoklady:
Jsou dány dva výběry o rozsazích n1, n2 s rozptyly s12, s22,
vybrané ze dvou základních souborů s rozděleními N(m1, s12) a N(m2, s22).
Nulová hypotéza:
H0: s12 = s22
Alternativní hypotéza:
H1: s12 ≠ s22
Testovací kritérium:
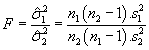
má Fisherovo-Snedecorovo rozdělení F(n1 - 1, n2 - 1).
Závěr:
Jestliže 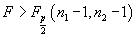 , zamítáme hypotézu H0 (přijímáme H1).
, zamítáme hypotézu H0 (přijímáme H1).
Indexy 1, 2 volíme tak, aby testovací kritérium F > 1.
Poznámka
V případě, že bychom chtěli prokázat hypotézu H0 proti hypotéze H1:
s12 > s22, použili bychom kritickou hodnotu
Fp(n1 - 1,n2 - 1)
Řešené úlohy
Příklad 12.2.1.
Byly sledovány výsledky běhu na 50 m (ve vteřinách) u skupiny desetiletých chlapců a dívek. Posuďte získané výsledky z hlediska vyrovnanosti výkonů v jednotlivých skupinách.
Chlapci:
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
| 10,80 |
9,30 |
9,40 |
9,90 |
10,20 |
9,30 |
9,40 |
8,90 |
8,90 |
9,60 |
9,70 |
10,60 |
9,40 |
9,50 |
9,60 |
10,00 |
9,30 |
| 18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
| 9,40 |
8,40 |
9,80 |
8,80 |
9,20 |
9,50 |
9,80 |
9,00 |
10,50 |
9,40 |
9,30 |
9,90 |
9,10 |
9,60 |
8,70 |
8,10 |
Dívky:
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
| 10,70 |
10,80 |
10,00 |
10,60 |
9,20 |
10,20 |
9,90 |
10,00 |
9,30 |
10,20 |
9,80 |
10,00 |
10,00 |
11,00 |
| 15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
| 12,00 |
10,00 |
10,00 |
11,20 |
9,40 |
10,70 |
9,30 |
10,10 |
9,10 |
10,20 |
9,30 |
10,00 |
9,40 |
10,90 |
Řešení:
Hladinu významnosti zvolíme
p = 0,05.
Určíme potřebné charakteristiky u obou skupin (prohodili jsme pořadí tak, aby vyšlo
F > 1):
Dívky:
n1 = 28
s12 = 0,4521 |
|
Chlapci:
n2 = 33
s22 = 0,3302 |
Určíme hodnotu testovacího kritéria:
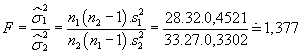
Kritická hodnota (vypočtená např. v Excelu pomocí předdefinované funkce
FINV):
F0,025(27,32) =
FINV(0,025;27;32) = 2,0689
Testovací kritérium nepřekročilo kritickou hodnotu, tudíž přijmeme
H0. Mezi rozptyly není statisticky významný rozdíl.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
12.3. Hypotézy o střední hodnotě
12.3.1. Test významnosti rozdílu |m - m0|
Předpoklady:
Je dán výběr ze základního souboru s rozdělením N(m, s2) o rozsahu n se střední hodnotou m a disperzí s2.
Nulová hypotéza:
H0: m = m0
Alternativní hypotéza:
H1: m ≠ m0
Testovací kritérium:

má Studentovo rozdělení t(n - 1).
Závěr:
Jestliže |T | > tp(n - 1), zamítáme hypotézu H0 (přijímáme H1).
Poznámka
Volíme-li alternativní hypotézu H1: m > m0 ,
pak hodnotu testovacího kritéria srovnáváme s kritickou hodnotou t2p(n - 1).
Řešené úlohy
Příklad 12.3.1.
V pivovaru došlo k opravě plnící linky. Na hladině významnosti p = 0,05 ověřte, zda se oprava zdařila, tj., zda linka plní do láhví pivo o objemu 500ml. Výsledky u vybraných vzorků (v mililitrech):
| 495,2 |
496,8 |
502,1 |
498,5 |
501 |
503 |
500,7 |
| 501,5 |
501,8 |
499,1 |
500,9 |
502,2 |
501,7 |
500,4 |
| 500,2 |
501,1 |
499,9 |
500,2 |
501,1 |
500,8 |
499,3 |
Řešení:
m0 = 500, tudíž:
H0:
m = 500
H1:
m ≠ 500
Výpočet základních charakteristik:
| n = 21 |
m = 500,3571 |
s = 1,77806 |
Testovací kritérium:
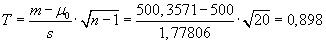
Kritická hodnota (vypočteme např. v Excelu pomocí předdefinované funkce
TINV):
t0,05(20) =
TINV(0,05;20) = 2,086
Závěr:
Testovací kritérium nepřekročilo kritickou hodnotu, tudíž přijmeme
H0. Oprava se zdařila, linka plní lahve správně.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
12.3.2. Test významnosti rozdílu dvou výběrových průměrů (t-test)
Předpoklady:
Jsou dány dva výběry o rozsazích n1, n2 se středními hodnotami m1, m2 a disperzemi s12, s22,
které pocházejí ze dvou základních souborů s rozděleními N(m1;s12) a N(m2;s22).
Nulová hypotéza:
H0: m1 = m2
Alternativní hypotéza:
H1: m1 ≠ m2
a) jestliže můžeme předpokládat
s12 =
s22
(prověříme
F-testem), volíme
testovací kritérium:
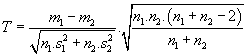
,
které má Studentovo rozdělení
t(
n1 +
n2 - 2).
Závěr:
Jestliže |
T | >
tp(
n1 +
n2 - 2), zamítneme
H0.
b) jestliže předpokládáme
s12 ≠
s22
(prověříme
F-testem), volíme
testovací kritérium:
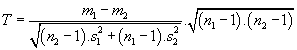
,
které má rozdělení, složené ze dvou Studentových rozdělení.
Kritické hodnoty určíme podle vzorce:
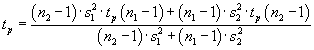 Závěr:
Závěr:
Jestliže |
T | >
tp, zamítneme
H0.
Poznámka
t-test používáme např. k ověřování následujících hypotéz:
- Pocházejí dva vzorky z téhož základního souboru?
- Nedopustili jsme se při dvou měřeních, jejichž výsledkem bylo určení dvou středních hodnot m1, m2, systematických chyb?
- Má určitý faktor vliv na zkoumaný argument? Zde zkoumáme dva vzorky - jeden při působení daného faktoru, druhý bez jeho působení.
Řešené úlohy
Příklad 12.3.2.
Odběratel dostává zářivky od dvou dodavatelů. Při hodnocení kvality zářivek se sleduje také
počet zapojení, který snesou zářivky bez poškození. Zkoušky výrobků vedly k těmto výsledkům:
| dodavatel A: |
2139 |
2041 |
1968 |
1903 |
1952 |
1980 |
2089 |
1915 |
| |
2389 |
2163 |
2072 |
1712 |
2018 |
1792 |
1849 |
|
| dodavatel B: |
1947 |
1602 |
1906 |
2031 |
2072 |
| |
1812 |
1942 |
2074 |
2132 |
|
Ověřte hypotézu, že kvalita obou dodávek je stejná. Hladinu významnosti volte p = 0,05.
Řešení:
V Excelu vypočteme charakteristiky obou souborů:
| n1 = 15 |
m1 = 1998,8 |
s12 = 25444,69 |
| n2 = 9 |
m2 = 1946,4 |
s22 = 23554,25 |
Nejdříve provedeme
F-test:
Testovací kritérium:
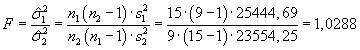
Kritická hodnota:
F0,025(14,8) =
FINV(0,025;14;8) = 4,1297
Přijmeme tedy hypotézu o shodě rozptylů
s12 =
s22.
Dále tedy postupujeme jako v případě
a):
Testovací kritérium:
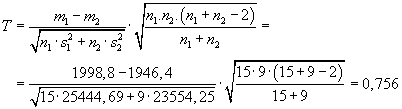
Kritická hodnota:
t0,05(22) =
TINV(0,05;22) = 2,074
Závěr:
Testovací kritérium nepřekročilo kritickou hodnotu, přijmeme
H0:
m1 =
m2. Kvalita obou dodávek je stejná.
Tato úloha se dá v Excelu řešit i jednodušším způsobem, máme-li nainstalován doplňkový nástroj Excelu
Analýza dat
(
instalace je podrobněji popsána v 7. kapitole, příkladu 7.3.1.). Tento doplněk by mělo být možné spustit z nabídky
Nástroje.
V dialogovém okně
Analýza dat klepneme na analytický nástroj
Dvouvýběrový t-test s rovností rozptylů. Objeví se nám okno, do kterého zadáme vstupy, tj. 1. soubor hodnoty od dodavatele
A,
2. soubor hodnoty od dodavatele
B. Výstupem pak bude následující (nebo velmi podobná) tabulka:

V této tabulce máme všechny potřebné údaje.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Příklad 12.3.3.
Při antropologických měřeních obyvatelstva Egypta byla mimo jiné sledována šířka nosu (cm) u skupiny
mužů 21-50 letých na severní části země a u skupiny stejně starých mužů z jižní části. Naměřené výsledky viz v tabulce.
Posuďte významnost rozdílu ve výsledcích. Hladinu významnosti volte p = 0,05.
| sever |
3,6 |
4,1 |
3,3 |
3,4 |
3,7 |
3,1 |
4,0 |
4,0 |
3,6 |
3,0 |
3,3 |
| |
3,7 |
4,3 |
3,3 |
3,4 |
3,4 |
3,3 |
3,6 |
4,0 |
3,4 |
3,7 |
|
| jih |
4,3 |
3,9 |
4,3 |
3,8 |
4,1 |
4,2 |
3,8 |
3,9 |
3,8 |
3,8 |
4,0 |
3,7 |
| |
3,9 |
4,4 |
3,7 |
3,8 |
3,9 |
3,9 |
4,0 |
4,1 |
3,8 |
4,0 |
4,3 |
|
Řešení:
V Excelu vypočteme charakteristiky obou souborů:
| n1 = 21 |
m1 = 3,580952 |
s12 = 0,112971 |
| n2 = 23 |
m2 = 3,973913 |
s22 = 0,0429249 |
Nejdříve provedeme
F-test:
Po dosazení do testovacího kritéria vyšla hodnota:
F = 2,763409
Kritická hodnota:
F0,025(20,22) =
FINV(0,025;20;22) = 2,38898
Tudíž nemůžeme přijmout hypotézu o shodě rozptylů:
s12 ≠
s22.
Dále tedy postupujeme jako v případě
b):
Testovací kritérium:
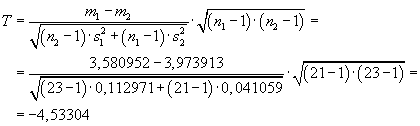
Kritická hodnota, po dosazení:
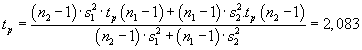
Závěr:
Testovací kritérium v absolutní hodnotě překročilo kritickou hodnotu, nemůžeme přijmout
H0. Šířky nosu na severu se liší od těch na jihu.
Stejně jako u předchozí úlohy můžeme vyřešit v Excelu i pomocí doplňkového nástroje
Analýza dat.
V dialogovém okně
Analýza dat klepneme na analytický nástroj
Dvouvýběrový t-test s nerovností rozptylů. Objeví se nám okno, do kterého zadáme vstupy, tj. 1. soubor hodnoty ze severní části země,
2. soubor hodnoty z jihu. Výstupem bude opět následující (nebo velmi podobná) tabulka:
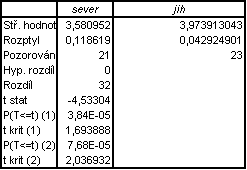
V této tabulce opět najdeme všechny potřebné údaje.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
12.3.3. Studentův test pro párované hodnoty
Předpoklady:
Ze dvou normálně rozložených základních souborů s parametry μ
1, σ
12
a μ
2, σ
22 byly vybrány dva výběry se stejnými rozsahy
n. Přitom
každému prvku prvého výběru
x1i odpovídá právě jeden prvek druhého výběru
x2i.
Vznikly tedy páry (
x1i ;
x2i),
i = 1, ...
n.
Nulová hypotéza:
H0: μ
1 = μ
2 ,
což lze jinak zapsat:
d = 0,
když
d je střední hodnota rozdílů
di =
x1i -
x2i , tedy:
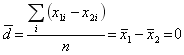
.
Alternativní hypotéza:
H1: μ
1 ≠ μ
2 nebo tedy:
d ≠ 0
Testovací kritérium:
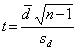
(
sd je směrodatná odchylka hodnot
di)
Veličina
t má Studentovo rozložení s
n - 1 stupni volnosti
t(
n - 1).
Závěr:
Jestliže |
t | >
tp(
n - 1), zamítneme hypotézu
H0.
Řešené úlohy
Příklad 12.3.4.
Stanovení thiocyanového iontu (SCN-) bylo paralelně provedeno dvěma metodami (Aldridge a Barker)
na 12 vzorcích. Srovnejte obě metodiky otestováním výsledků. Hladina významnosti p = 0,05.
| |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
| Aldridge |
0,38 |
0,56 |
0,45 |
0,49 |
0,38 |
0,41 |
0,6 |
0,36 |
0,26 |
0,41 |
0,43 |
0,4 |
| Barker |
0,39 |
0,58 |
0,44 |
0,52 |
0,41 |
0,45 |
0,59 |
0,37 |
0,28 |
0,42 |
0,42 |
0,38 |
Řešení:
Nejprve vytvoříme veličinu d:
| Aldridge |
0,38 |
0,56 |
0,45 |
0,49 |
0,38 |
0,41 |
0,6 |
0,36 |
0,26 |
0,41 |
0,43 |
0,4 |
| Barker |
0,39 |
0,58 |
0,44 |
0,52 |
0,41 |
0,45 |
0,59 |
0,37 |
0,28 |
0,42 |
0,42 |
0,38 |
| di |
-0,01 |
-0,02 |
0,01 |
-0,03 |
-0,03 |
-0,04 |
0,01 |
-0,01 |
-0,02 |
-0,01 |
0,01 |
0,02 |
Z tabulky jednoduše vypočteme potřebné charakteristiky:
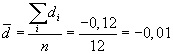
(nebo v Excelu pomocí funkce
PRŮMĚR)
Obdobně směrodatnou odchylku:
sd = 0,018257
Testovací kritérium:
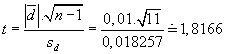
Kritická hodnota:
t0,05(12 - 1) =
TINV(0,05;11) = 2,201
Testovací kritérium nepřekročilo kritickou hodnotu, přijmeme
H0. Obě metodiky dávají stejné výsledky.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Přejděme nyní k ukázkám testů neparametrických, u nichž se nezaměřujeme na hodnoty některých parametrů základního souboru,
ale studujeme shodu rozložení náhodné veličiny. Ověřujeme tedy např., zda určitý teoretický základní soubor může být modelem
pro studovaný výběr, zda rozložení těchto souborů je možno považovat za totožná. Předveďme některé testy dobré shody.
12.4. Testy dobré shody (testy přiléhavosti)
12.4.1. Pearsonův test dobré shody - χ2 test pro jeden výběr
Předpoklady:
Nechť výsledky pozorování jsou roztříděny do
k skupin a v každé skupině je zjištěna skupinová četnost
fej
(četnosti experimentální). Uvažujme určité rozdělení, které budeme považovat za model pro náš výběr. Pro každou třídu určíme teoretické,
modelové, očekávané četnosti
foj (j = 1,...,k).
Nulová hypotéza:
H0: Základní soubor má očekávané rozložení, tzn. že četnosti
fej a
foj (
j = 1,...,
k) se liší
pouze náhodně.
Testovací kritérium:
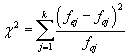
Tato veličina má Pearsonovo rozložení χ
2 s ν =
k -
s - 1 stupni volnosti. Veličina
s
značí počet parametrů očekávaného rozložení odhadnutých na základě výběru.
Závěr:
Jestliže χ
2 > χ
p2(
k -
s - 1), zamítneme hypotézu
H0.
Poznámky
Při použití tohoto testu se vyžaduje splnění těchto podmínek:
- všechny očekávané třídní četnosti mají být větší než 1,
- nejvýše 20 % očekávaných třídních četností může být menších než 5,
- nedoporučuje se volit počet tříd větší než 20.
Nejsou-li splněny, lze přikročit k sloučení sousedních tříd v nezbytném rozsahu.
Pozn. ke stupňům volnosti: Ověřujeme-li např. normalitu základního souboru, je
s rovno 2, protože teoretické normální rozložení se stanovuje
na základě odhadu střední hodnoty a disperze výběru, tedy na základě dvou charakteristik.
Řešené úlohy
Příklad 12.4.1.
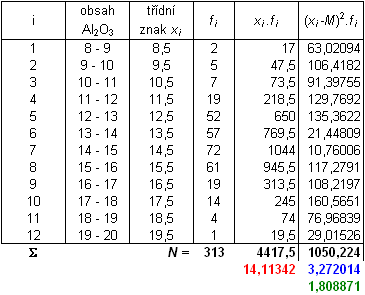
Je dán statistický soubor:
| i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
| obsah Al2O3 |
8-9 |
9-10 |
10-11 |
11-12 |
12-13 |
13-14 |
14-15 |
15-16 |
16-17 |
17-18 |
18-19 |
19-20 |
| fei |
2 |
5 |
7 |
19 |
52 |
57 |
72 |
61 |
19 |
14 |
4 |
1 |
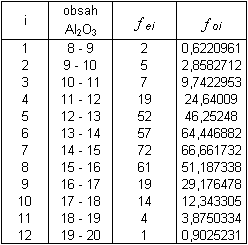
Na hladině významnosti 5 % otestujte hypotézu, že soubor má normální rozdělení.
Řešení:
Nejdříve vypočteme příslušné charakteristiky, tj. parametry normálního rozdělení - střední hodnotu a rozptyl.
Výpočet provedeme způsobem, který byl popsán v
7. kapitole, příkladu 7.4.1.:
Střední hodnota:
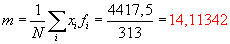
Rozptyl:
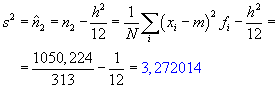
Směrodatná odchylka:
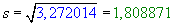
Pomocí parametrů normálního rozdělení můžeme vypočítat očekávané četnosti
foi:
Uvedeme např. výpočet
fo1:
fo1 =
N.P(8 ≤
X ≤ 9) = 313.(
F(9) -
F(8)) = (v Excelu) =
=
313*(NORMDIST(9;14,11342;1,808871;1) -
- NORMDIST(8;14,11342;1,808871;1)) =
= 0,6220961
Zbylé očekávané četnosti vypočteme analogicky, viz. tabulka:
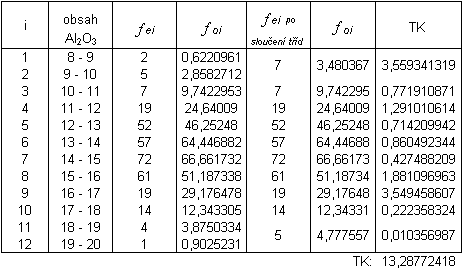
Z tabulky je patrné, že nejsou splněny všechny podmínky z předchozí poznámky, proto sloučíme třídy 1,2 a třídy 11,12:
Po sloučení tříd jsou všechny podmínky splněny, v posledním sloupci je vypočtena hodnota testovacího kritéria:
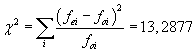
Kritická hodnota:
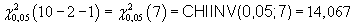
Závěr:
Testovací kritérium nepřekročilo kritickou hodnotu.
Daný soubor má normální rozdělení.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
12.4.2. Kolmogorovův-Smirnovův test dobré shody pro jeden výběr
Předpoklady:
Nechť výsledky pozorování jsou roztříděny do
k skupin a v každé skupině je zjištěna skupinová četnost
nej
(četnosti experimentální). Uvažujme určité rozdělení, které budeme považovat za model pro náš výběr. Pro každou třídu určíme teoretické,
modelové, očekávané četnosti
noj (
j = 1,...,
k).
Pro empirické i teoretické očekávané rozdělení stanovíme kumulativní četnosti
Nej a
Noj,
j = 1,...,
k.
Nulová hypotéza:
H0: Základní soubor má očekávané rozložení, tzn. že četnosti
Nej a
Noj (j = 1,...,k) se liší
pouze náhodně.
Testovací kritérium:
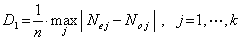
Tato veličina má speciální rozložení, jehož kritické hodnoty jsou tabelovány pro
n < 40
(viz tabulky). Pro
n ≥ 40 se počítají podle přibližných vzorců.
Pro hladinu významnosti
p = 0,05 je
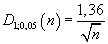
,
pro hladinu významnosti
p = 0,01 je
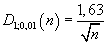 Závěr:
Závěr:
Jestliže
D1 ≥ D
1;p, zamítneme hypotézu
H0.
Řešené úlohy
Příklad 12.4.2.
Využijeme zadání příkladu 12.4.1. a úlohu vyřešíme pomocí Kolmogorovova - Smirnovova testu pro jeden výběr:
Řešení:
Parametry normálního rozdělení a očekávané četnosti jsme už vypočetli v příkladě 12.4.1., stačí dopočítat kumulativní četnosti a testovací kritérium:
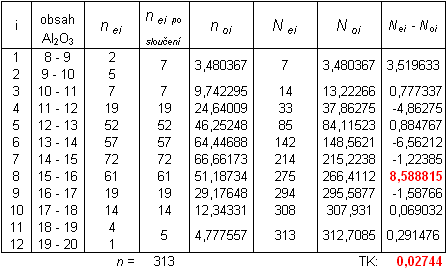
Testovací kritérium:
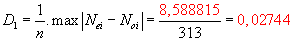
.
Kritická hodnota:
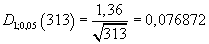
.
Testovací kritérium nepřekročilo kritickou hodnotu.
Daný soubor má normální rozdělení.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Předchozí dva testy ověřovaly, zda rozložení výběru neodporuje předpokladu o určitém rozložení základního souboru. Následující test
bude ověřovat, shodu rozložení dvou výběrů.
12.4.3. Kolmogorovův-Smirnovův test dobré shody pro dva výběry
Předpoklady:
U dvou výběrových souborů s rozsahy
n1 a
n2 bylo provedeno roztřídění do
k skupin a zjištěny kumulativní
třídní četnosti pro každou třídu:
N1,j a
N2,j.
Nulová hypotéza:
Oba výběrové soubory mají totéž rozložení (pocházejí tedy z téhož základního souboru).
Testovací kritérium:
a)
n1 =
n2 ≤ 40
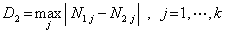
má speciální rozložení, jeho kritické hodnoty se vyčtou z příslušných tabulek
(viz tabulky),
)
n1 > 40 a
n2 >40 (i různě velké):
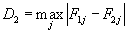
.
Kritické hodnoty se počítají podle vzorců:
pro
p = 0,05 je
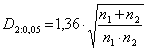
a
pro
p = 0,01 je
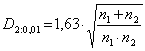
.
Závěr:
Jestliže
D2 ≥
D2:p(
n1,
n2), zamítneme nulovou hypotézu
H0.
Řešené úlohy
Příklad 12.4.3.
Ve dvaceti vybraných závodech byly zkoušeny dva typy filtrů odpadních vod. Bylo zjišťováno, jaké procento nečistot filtr zadrží, a to tak,
že nejprve byly instalovány filtry 1. typu a po určité době filtry 2. typu. Výsledky jsou v tabulce:
množství
zadržených
nečistot (v %) |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
| n1,j |
1 |
2 |
3 |
8 |
5 |
1 |
0 |
| n2,j |
0 |
2 |
3 |
2 |
3 |
7 |
3 |
Zjistěte, jestli se porovnávané filtry kvalitativně liší.
Řešení:
H0: Dva základní soubory mají totéž rozdělení (porovnávané filtry se kvalitativně neliší).
Volíme hladinu významnosti p = 0,05
množství
zadržených
nečistot (v %) |
n1,j |
n2,j |
N1,j |
N2,j |
|N1,j - N2,j| |
| 10 |
1 |
0 |
1 |
0 |
1 |
| 20 |
2 |
2 |
3 |
2 |
1 |
| 30 |
3 |
3 |
6 |
5 |
1 |
| 40 |
8 |
2 |
14 |
7 |
7 |
| 50 |
5 |
3 |
19 |
10 |
9 |
| 60 |
1 |
7 |
20 |
17 |
3 |
| 70 |
0 |
3 |
20 |
20 |
0 |
Z tabulky vidíme, že
n1 =
n2 < 40, tudíž testovací kritérium:
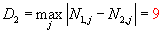
Kritická hodnota:
D2;0,05(20) = 9
(viz tabulky)
Závěr:
D2 =
D2;0,05(20) = 9, zamítneme
H0.
Filtry se kvalitativně liší.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Existují i neparametrické testy, které neověřují rozložení výběrového souboru. Uveďme test, který se snaží zjistit, zda výběrový soubor
neobsahuje údaj zatížený hrubou chybou měření, popř. chybou v zápise. Jde o jeden z testů extrémních odchylek.
12.5. Testy extrémních hodnot
12.5.1. Dixonův test extrémních odchylek
Předpoklady:
Ve výběrovém souboru o rozsahu
n je
x1 = min(
xi), resp.
xn = max(
xi) (např. hodnoty jsou seřazeny podle velikosti od
x1 do
xn).
Nulová hypotéza:
H0: Hodnota
x1 (nejmenší hodnota), resp.
xn (největší hodnota) se neliší významně od ostatních hodnot souboru.
Testovací kritérium:
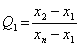
, nebo
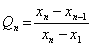
,
podle toho, testujeme-li minimální nebo maximální hodnotu ve výběru.
Kritické hodnoty
Q1;p, resp.
Qn;p se vyčtou z příslušných tabulek
(viz tabulky).
Závěr:
Jestliže
Q1 >
Q1;p ,
resp.
Qn >
Qn;p, zamítneme nulovou hypotézu
H0.
Test extrémních odchylek je možno ovšem také provést užitím parametrického testu:
12.5.2. Grubbsův test extrémních odchylek
Předpoklady:
Ve výběrovém souboru o rozsahu
n je
x1 = min(
xi), resp.
xn = max(
xi) (např. hodnoty jsou seřazeny podle velikosti od
x1 do
xn).
x je střední hodnota výběru,
S je výběrová směrodatná odchylka.
Nulová hypotéza:
H0: Hodnota
x1, resp.
xn se neliší významně od ostatních hodnot souboru.
Testovací kritérium:
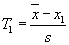
, resp.
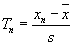
,
podle toho, testujeme-li minimální nebo maximální hodnotu ve výběru.
Kritické hodnoty
T1;p, resp.
Tn;p se vyčtou z příslušných tabulek
(viz tabulky),
Závěr:
Jestliže
T1 >
T1;p ,
resp.
Tn >
Tn;p, zamítneme nulovou hypotézu
H0.
Poznámka
Vede-li test k závěru, že extrémní hodnotu je třeba ze souboru vyloučit, je třeba sestrojit znovu všechny výběrové charakteristiky (ze souboru bez extrémní hodnoty) pro
případné další výpočty.
Řešené úlohy
Příklad 12.5.1.
Při kalibraci titrační metody k stanovení krevního cukru bylo provedeno 12 paralelních analýz z jednoho vzorku
s těmito výsledky:
| 83 |
88 |
84 |
78 |
82 |
82 |
| 86 |
81 |
98 |
83 |
85 |
80 |
Otestujte, zda hodnota 98 není chybná.
Řešení:
Dixonovým testem:
x1 = 78 (nejmenší hodnota)
xn - 1 = 88 (druhá největší hodnota)
Testovací kritérium:
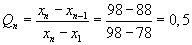
Kritická hodnota:
Q12;0,05 = 0,376;
Q12;0,01 = 0,482
(viz tabulky).
Závěr:
Testovací kritérium překročilo kritickou hodnotu (pro obě zkoumané hladiny významnosti). Zamítáme nulovou hypotézu
H0.
Hodnota 98 se významně liší od ostatních hodnot.
Grubbsovým testem:
Nejdříve vypočteme potřebné charakteristiky:
| x = 84,16667 |
s = 4,896144 |
Testovací kritérium:
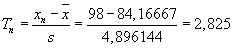
Kritická hodnota:
Q12;0,05 = 2,387;
Q12;0,01 = 2,663
(viz tabulky).
Závěr:
Testovací kritérium překročilo kritickou hodnotu (pro obě zkoumané hladiny významnosti). Zamítáme nulovou hypotézu
H0.
Hodnota 98 se významně liší od ostatních hodnot.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
Uveďme ještě test, který se týká koeficientu korelace u dvojrozměrné náhodné veličiny.
12.6. Testy o koeficientu korelace
12.6.1. Test lineární nezávislosti v základním souboru
Předpoklady:
Dvojrozměrný základní soubor má normální rozložení a korelační koeficient
ρ.
Náhodný výběr z tohoto souboru má rozsah
n a koeficient korelace
r.
Nulová hypotéza:
ρ = 0
Testovací kritérium:
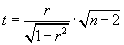
Tato veličina má Studentovo rozložení s
n - 2 stupni volnosti
t(
n - 2).
Závěr:
Jestliže
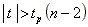
, zamítneme
H0.
Poznámka
Odmítnutí nulové hypotézy znamená připuštění alternativní hypotézy, že mezi složkami náhodné veličiny je korelace, nejsou
lineárně nezávislé.
Řešené úlohy
Příklad 12.6.1.
Otestujte na hladině významnosti p = 0,05, zda u dvojrozměrné veličiny dané v tabulce, může jít o lineární závislost.
| x |
0,0 |
0,5 |
1,0 |
1,5 |
2,0 |
2,5 |
3,0 |
| y |
0,0 |
1,7 |
3,1 |
3,8 |
3,9 |
3,8 |
3,0 |
Řešení:
Použijeme předchozí test lineární nezávislosti v základním souboru.
Nejdříve (např. v Excelu vypočteme výběrový koeficient korelace:
R = 0,752064.
Tuto hodnotu dosadíme do testovacího kritéria:
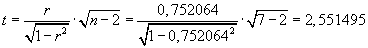
.
Kritická hodnota:
t0,05(7-2) =
TINV(0,05;D22) = 2,570582.
Závěr:
Hodnota testovacího kritéria nepřekročila kritickou hodnotu.
Není nutno zamítnout hypotézu o lineární nezávislosti
x a
y.
Tuto úlohu si zde můžete otevřít
vyřešenou v Excelu.
K procvičení předchozích poznatků si otevřete
sbírku úloh, ve které najdete mnoho řešených i neřešených příkladů z matematické statistiky.