Project # 2
Assignment
The goal of the project is the implementation of the Mean Shift clustering algorithm.
Problem description. Mean Shift is a clustering algorithm based on the principle of finding places in the dataset where the local density of points (vectors) is maximal. At each step, the algorithm moves in the direction of the weighted average of the samples (center of gravity) from the area around the current position.
When used for clustering, a simple variant of the Mean Shift algorithm can be described in two steps:
- from each point we run Mean Shift and remember the centroid to which it converged.
- points that have converged to the same point (with a certain tolerance) are marked as members of one cluster.
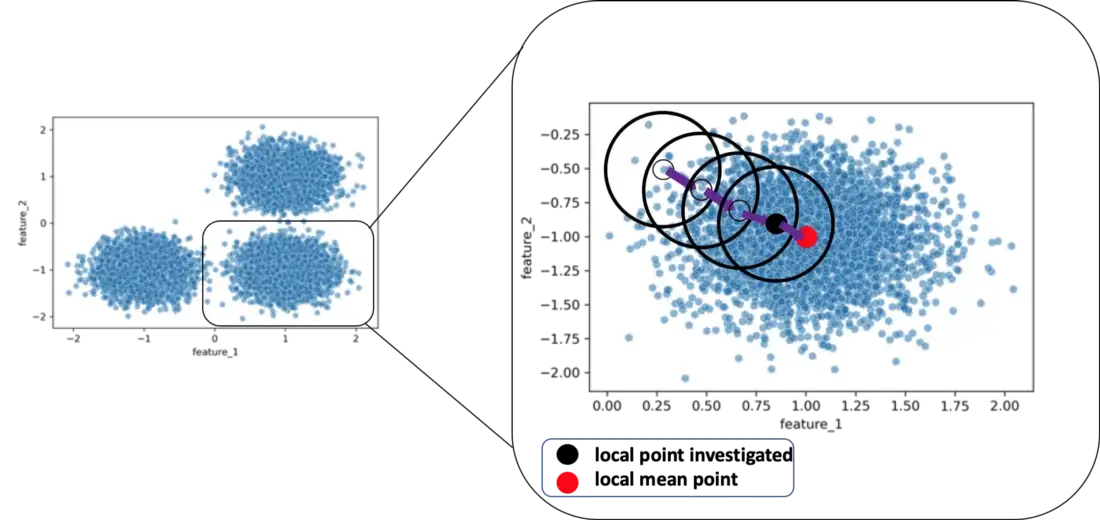
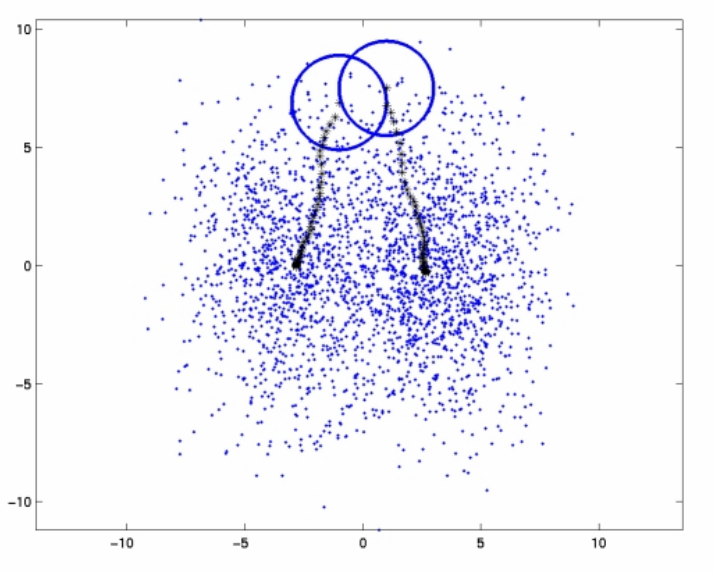
The Mean Shift algorithm calculates in each step the gradient of the point density at the current position in the current window (a sphere in n-dimensional space) based on some kernel (radially symmetric function), \(K\), and the specified window size and moves the examined point to that location. The kernel determines the weight of the contribution of points in the sphere to determine the new centroid based on their distance from the current point
The displacement of the position towards the area with the highest density of points can be defined as \[m_h(\vec{x}) = \frac{\sum_{x_i\in N(x)}K(\vec{x}_i - \vec{x}, \sigma)\vec{x_i} }{\sum_{x_i\in N(x)}K(\vec{x}_i - \vec{x}, \sigma)},\] where \( N(\vec{x}) \) is the neighborhood of the point \( \vec{x} \), ie, the set of points for which it holds \( K(\vec{x}) \neq 0 \). A Gaussian function of the following form is often used as a kernel \[K(d, \sigma) = \frac{1} { \sigma \sqrt{2\pi}} e^{-\frac{d^2} {2\sigma^2}},\] where the parameter \( \sigma \) corresponds to the window size (bandwidth) and \(d\) to distance.
Based on the description of Mean Shift, we can formulate the following assignment.
Assignment. Implement the Mean Shift solution (e.g., on part of the MNIST dataset) with a Gaussian kernel. You can find the description of the dataset here (original) or here (a simpler format). The goal of the task is not to learn how to cluster MNIST by real classes, but to implement and test an implementation of the algorithm. So we can ignore the class label for clustering purposes. It can be used to verify how many clusters the algorithm finds and how correctly it assigns objects.
References
- D. Comaniciu and P. Meer. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Machine Intell., 24:603–619, 2002
- https://www.kaggle.com/code/subhamsharma96/clustering-meanshift/notebook