Informace k předmětu
Přednášky a další informace na stránkách doc. Dvorského odkaz
Bodování
Klasifikovaný zápočet
30 bodů za aktivní plnění úloh ze cvičení
70 bodů za vypracování a odevzdání projektu
30 bodů za aktivní plnění úloh ze cvičení
70 bodů za vypracování a odevzdání projektu
Cvičení
19-20.2 - Vyhledávání řetězců hrubou silou a pomocí knihoven programovacích jazyků (2 body - AI povolena)
- Naimplementujte vyhledávání hrubou silou - Example.
- Pomocí svého oblíbeného jazyka a nějaké jeho funkce, najděte všechny výskyty hledaného řetězce v textu.
- Zjistěte jaký algoritmus se používá v implementaci funkce pro lokalizaci hledaného řetězce. (1 bod)
- Stáhněte si testovací sadu textů: Dataset
- Vyhledejte libovolné slovo v testovacích datech a změřte čas, jak dlouho trvá vyhledání hrubou silou a jak dlouho implementace ve vašem oblíbeném programovacím jazyku.(1 bod)
26-27.2 - Vyhledávání pomocí deterministického konečného automatu (2 body, 1 bonusový bod)
- Nastudujte si algoritmus popsaný v Handbok of Exact String Matching Algorithms - strana 25, Kapitola: Search with an automaton
- Implementujte deterministický konečný automat, který bude reprezentovat hledaný vzor. Následně tento vzor vyhledejte v textu a vraťte pozice daného vzoru v textu. (1 bod)
- Změřte čas pro vyhledání libovolného řetězce a porovnejte dosažené časy s algoritmem hledání hrubou silou. (1 bod)
- Bonusová úloha - Vyhledání regulárního výrazu. Uvažujte regulární výraz připouštějící použití závorek, operátoru | (reprezentující nebo) a operátor * (značící libovolný počet výskytů). Např. a(b|c)* značí slovo začínající na "a" a pokračující libovolným počtem opakování "b" nebo "c". Postup by měl být následující, převeďte regulární výraz na nedeterministický konečný automat, ten následně na deterministický a pomocí deterministického již můžete vyhledávat. (1 bod - AI povolena)
4.3 - Vyhledávání řetězců: Boyer-Moore-Horspool (2 body)
- Nastudujte si a naimplementujte následující algoritmus BMH(1 bod)
- Vyberte si jeden z 50 MB souborů z datasetu níže. Vygenerujte náhodně 100 slov z vybraného datasetu, která následně vyhledáte pomocí algoritmů: Naivní, Konečný automat, BMH, porovnejte čas vyhledání.(1 bod)
- Testovací data:
- Literatura:
11.3 - Vyhledávání s chybou (4 body)
- Implementujte nedeterministický konečný automat pro vyhledávání s chybou pro až k chyb.
- Postupným průchodem textem: English nalezněte všechny výskyty slova s přednastaveným počtem chyb.(4 body)
- Kód otestujte.
- Literatura:
- Hlavní zdroj: Overview of methods, Navarro 1999 - page 25-26
- Další používané metody: Introduction to Information Retrieval - Chapter 3
- Poznámky k implementaci:
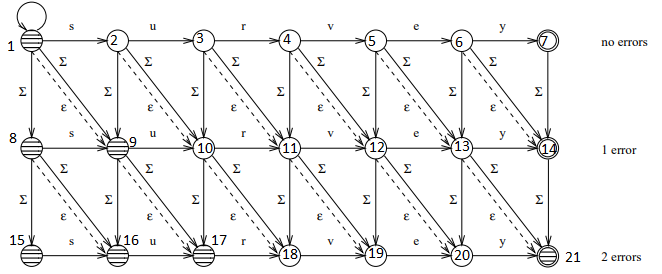
- Automat je nedeterministický => budete muset vyzkoušet všechny průchody automatem.
- Při řešení lze využít rekurze.
- Na obrázku můžete vidět, že pokud si jednotlivé stavy očíslujeme, pak lze celý proces řešit pouze s využitím celočíselných operací:
- Ověření, že aktuální stav je přijímajícím stavem, lze vyřešit operací dělení se zbytkem: state_number % (len(pattern) + 1) == 0
- Přechod z jednoho stavu do dalšího lze řešit přičtením předpočítané hodnoty:
- Shoda symbolů: next_state = current_state + 1
- Neshoda symbolů nebo chybějící symbol, diagonální posun: next_state = current_state + len(pattern) + 2
- Nadbytečný symbol, posun dolů: next_state = current_state + len(pattern) + 1
- Pokud umožníme algoritmu počítat až s k chybami, pak počet stavů bude: (k+1)*(len(pattern)+1)
- Při výberu cest, které procházíme nejdříve preferujeme cesty vedoucí k menšímu počtu chyb => hledáme průchod s nejmenším počtem chyb.
- Pokud tedy všechny tyto znalosti poskládáme, tak zjistíme, že pro implementaci algoritmu nám stačí znát slovo (může obsahovat chyby) zadané uživatelem a ve funkci provádějící porovnání vůči aktuální pozici v textu, pak udržovat seznam dvojic (aktuální číslo stavu, pozice v textu vůči počáteční pozici), který postupně rozšiřujeme (odebereme aktuální stav a přidáme dvojice reprezentující nové dostupné stavy), tak jak procházíme jednotlivé stavy.
18.3 - Předzpracování Textu (2 body)
- Úkoly
- Vyberte si jednu z kolekcí dokumentů níže, případně si připravte vlastní kolekci dokumentů.
- Prostudujte si kolekci: anotace a strukturování dokumentů. Připravte metody pro extrakci textu.
- Odstraňte interpunkční a další speciální znaky, v kolekci nechte pouze alfanumerické symboly. Velká písmena převeďte na malá.
- Implementujte Stop list: Introduction to Information Retrieval - Chapter 2 page 26
- Uložte si předzpracované dokumenty do oddělených souborů.
- Testovací Kolekce:
- Reuters newsletter
- Wikipedia dump
- English books from project Gutenberg
- English books from project Gutenberg - download script
- Porter Stemmer
- Použijte předzpracovanou kolekci.
- Implementujte nebo přidejte do svého kódu Porter Stemmer: Popis algoritmu (Zdrojové kódy)
25.3 - Invertovaný index (4 body)
- Připravte invertovaný index:
- Vytvořte pole: (term, docID).
- Setřiďte pole pomocí termu a docID.
- Stejné dvojice (term,docID) odstraňte.
- Pro každý term vytvořte seznam dokumentů, ve kterých se vyskytuje: (term: docID1, docID2,...).
- Ke studiu: Introduction to Information Retrieval - Chapter 1 pages 7-9 for more details.
- Dotazovací systém:
- Připravte metody pro zpracování AND dotazů pomocí algoritmu pro průnik seznamů.: viz. Introduction to Information Retrieval - Chapter 1, Figures 1.6 and 1.7, pages 11-12.
- Otázka: query = word1 AND word2 AND word3, |p1| > |p2| > |p3|, kde p1,p2 a p3 jsou délky seznamu dokumentů pro jednotlivá slova, které z těchto vyhodnocení proběhne rychleji:
- (word1 AND word2) AND word3
- word1 AND (word2 AND word3)
- Otestujte svou implementaci.
- [Volitelně] Implementujte OR a NOT dotazy.
8-9.4 - Komprese Invertovaného Indexu(2 body)
- Komprese seznamu dokumentů - implementujte jeden z následujích algoritmů
- Eliasovo gamma kódování
- Fibonacciho kódování
- Vygenerujte si slovnik s 1000 nahodnymi slovy, predpokladejte kolekci s 10000 dokumenty. Nahodne si vygenerujte milion unikatnich dvojic (slovo, docID) a sestavte senzam docIDs. Zakodujte zvolenym algoritmem, jako sekvenci rozdilu mezi dvema po sobe jdoucimi docID.
- Porovnejte velikost zakodovaneho seznamu s velikosti nezakodovaneho seznamu.
- Jedotlivá kódová slova ukládejte ve formě textové reprezentace, není třeba je reprezentovat binárně.
- Kódy s proměnlivým počtem bytů. Prezentace ACS | Introduction to Information Retrieval - Chapter 5 pages 96-98
- Další zdroje:
- Porovnání různých prefixových kódů: link
15.4 - Vektorový Model - 1 (5 bodů)
- Použijte předpřipravenou kolekci
- Spočítejte term frequency tf_t_d pro každý term 't' v každém dokumentu 'd'.
- Spočítejte inverse document frequency idf_t = log(N/df_t), kde N je počet dokumentů v kolekci a 'df_t' je počet dokumentů obsahujích term 't'.
- Spočítejte tf-idf váhy: tf-idf_t_d = tf_t_d * idf_t
- Spočítejte skóre pro termy v dotazu q: Score(q,d) = sum_t_in_q tf-idf_t_d
- Vraťte 10 dokumentů s nejvyšším skóre.
- Další zdroje: