Tyto texty se zabývají partiemi matematické statistiky, kterými se statistické zpracování environmentálních dat výrazně odlišuje od zpracování dat "normálních". Environmentální data - stejně jako většina dat vázaných na zemský povrch - mají zřetelně stochastický charakter. Z takových dat sice lze formálně spočítat běžně používané statistické charakteristiky (jako např. aritmetický průměr nebo rozptyl), ale praktická využitelnost takových čísel je většinou nulová.
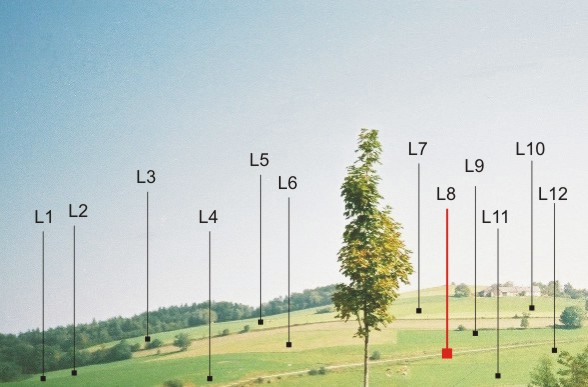
Uveďme příklad. Mějme krásné horské pastviny. Zkoumejme kvalitu půdy odběrem vzorků ve dvanácti lokalitách podle následujícího obrázku:
Obr. 12.1.1: Lokality odběru vzorků
V laboratoři byly provedeny rozbory na přítomnost nejrůznějších znečišťujících látek. Tak například obsah olova vyjádřený koncentrací v [ppm] (=[mg/kg]) udává následující tabulka:
|
Koncentrace Pb |
|||||
| Lokalita | Pb | Lokalita | Pb | Lokalita | Pb |
| L1 | 25 | L5 | 25 | L9 | 10 |
| L2 | 16 | L6 | 4 | L10 | 9 |
| L3 | 5 | L7 | 8 | L11 | 15 |
| L4 | 14 | L8 | 12 552 | L12 | 21 |
Tab.12.1.1: Obsah znečišťující látky
Z tabulky vyplývá, že průměrná hodnota znečištění olovem je v celém zkoumaném terénu 1058,7 [ppm]! Uvážíme-li, že hygienická norma stanoví pro olovo limit (celková koncentrace ve vzorku pro lehké půdy) 100 [ppm], je závěr učiněný na základě aritmetického průměru jednoznačný: celý kopec okamžitě uzavřít lidem i zvěři.
Jestliže však budeme případ zkoumat dále, zjistíme tento fakt: v lokalitě L8 je proto tak vysoká hodnota olova, protože před týdnem se na tom místě (těsně vedle polní cesty) vymlel borec na mopedu a vytekla mu skoro celá nádrž. Dobrá; stačí vyčistit kubík půdy. To ale znamená, že L8 rozhodně nemá stejný charakter jako ostatní lokality odběru (je anomální) a protože známe důvod, vyloučíme L8 ze zpracování. Aritmetický průměr zbývajících hodnot pak dá příjemných 13,8 [ppm].
Uvedený příklad ukazuje častý případ chybného chování zpracovatele dat. Prozkoumání dat totiž musí být provedeno před jejich statistickým zpracováním už z toho prostého důvodu, že každá statistická metoda dává korektní výsledky jen za splnění jistých předpokladů o zpracovávaných datech. Nejsou-li předpoklady splněny, nemá na daná data smysl metodu použít. Např. pro použití aritmetického průměru musí data splňovat podmínku normálního rozdělení (viz dále), a ta u dat v tabulce 1.1 splněna není.
Zvláště velké (protože skryté) je toto nebezpečí v současnosti, v době masivního používání osobních počítačů pro téměř cokoliv. Existuje řada výborných programů pro nejrůznější statistická zpracování. Tyto programy poskytují většinou nejen numerické, ale hlavně grafické výstupy. Zejména prostorové modely patřičně spektrálně kolorované jsou čarokrásné a okouzlí běžného uživatele nejen svým vzhledem, ale hlavně snadností jejich získání. Jen považte: zadáme dvanáct čísel, stiskneme knoflík - a vědecky věrohodný nádherný výstup je zde!
Zmíněné nebezpečí spočívá právě ve zdánlivé lehkosti zpracování dat. Programy používají jisté statistické metody (důkladně popsané v manuálu programu) předpokládající jistý charakter dat. Jestliže uživatel programu neověří, zda data předpoklady splňují, nemá smysl metody používat.
Další kapitoly popisují proto některé postupy při statistickém zpracování geochemických dat, podávají definici (vybraných) jak běžně používaných, tak specifických statistických pojmů a vysvětlují jejich použití tak, aby se předešlo shora nastíněné chybné interpretaci.
Práce není klasickou učebnicí statistiky. Vybírá jen některé partie některých podoborů, a to zcela účelově zaměřené na nejobvyklejší požadavky zpracování geochemických dat. V teorii pravděpodobnosti tak zcela chybí obvyklé házení dvěmi kostkami nebo vybírání kuliček z pytlíku, v matematické statistice se např. z rozdělení zmiňuje jen normální rozdělení apod. Naopak uvádí některé postupy běžně nepublikované, ale hojně používané v současných počítačových aplikacích charakteru geografických informačních systémů a jiných - těch, se kterými se setkáváme v praxi environmentálního inženýrství a aplikované geochemii.