Náhodná veličina x je taková veličina, která může nabývat obecně více hodnot z nějaké množiny X, a to každé s nějakou pravděpodobností - přičemž to, které hodnoty nabude, je ovlivněno náhodnými vlivy. Zkoumanými jevy jsou pak např. x = a nebo a Ł x Ł b apod.
Poznámka: Velmi často - a shora už je to naznačeno - se zcela automaticky ztotožňují pojmy veličina a hodnota veličiny. Zřejmé je to např. v zápise xÎX - rozumí se tím, že ne sama veličina x, ale její hodnota patří do nějaké množiny hodnot X.
V každodenní praxi se environmentální inženýr setkává s řadou jevů, které hodnotí z hlediska příčin vzniku a dopadu na jevy jiné. Dělá to pomocí dat popisujících každý jev především právě teď v tomto místě, ale také z dat, které popisovaly jev jednak dříve, jednak na jiných místech. Evidentně aktuální stav nějakého jevu v aktuálním okamžiku - a environmentálního jevu zvlášť - je podmíněn řadou jiných jevů, které jsou se sledovaným jevem v interakci.
Řada jevů v přírodních vědách je relativně dobře prozkoumatelná a předvídatelná. Např. délková roztažnost kovové tyče je popsána materiálem a teplotou. Z několika známých stavů tohoto jevu lze jev popsat zcela přesně. U environmentálních jevů je však situace zcela odlišná. U nich totiž často nelze ani vyjmenovat jevy, které na sledovaný jev působí, natož je kvantifikovat.
Přesto je zapotřebí jevy zkoumat a předvídat, a to na základě údajů, které jsou o jevu k disposici resp. jejichž sběr se cílevědomě zajišťuje. Shromážděné údaje jsou hodnoty veličin, o kterých environmentální odborníci usuzují, že právě ony jev charakterizují. Tyto veličiny se však již dále samostatně nezkoumají, přijímají se takové, jaké jsou. Jejich hodnoty mohou nabývat (v rámci fyzikálních, chemických a jiných zákonů) jakékoliv hodnoty. Proto se i na environmentální jevy pohlíží jako na jevy náhodné, stochastické, a statistika je pak vědou o zjišťování, zpracování a analýze numerických údajů tyto jevy popisující. Matematická statistika vypracovává metody založené na předpokladu, že zjištěná data jsou výsledkem interakce náhodných veličin. Metody pak vedou k bližšímu určení některých neznámých parametrů v zákonech rozdělení pravděpodobnosti zkoumaných jevů.
Uvažujme např. kvalitu povrchových vod definovaných třídou jakosti podle českých i mezinárodních norem. Povrchovou vodu zařazuje do třídy jakosti obsah normami stanovených látek. Nechť řeka Odra v Jakubčovicích hypoteticky neobsahuje kromě H2O naprosto žádné jiné látky, tedy je třídy I. Jestliže z kamenolomu nad Jakubčovicemi spadne do Odry barel nafty, je zřejmé, do jaké třídy Odra klesne. Přitom postupné znečišťování Odry lze v tomto případě naprosto přesně modelovat na základě znalosti objemu barelu, časového režimu odtoku nafty z barelu daného průměrem nalévacího otvoru a prostorového umístění barelu v řece apod.
Jenomže toto obyvatelé Jakubčovic neví. Prostě najednou, z ničeho nic, je voda z Odry naprosto nepoužitelná. Pro ně to je náhoda. Oni příčinu nezkoumají, berou stav takový, jaký je. I opětné samovolné vyčištění je pro ně náhodné - najednou je voda zase čistá, i když i tento jev je dobře modelovatelný. Zatímco tedy obyvatelé berou jev jako náhodný, vodohospodáři jsou schopni - i když ne zrovna jednoduše - jev přesně popsat.
Vezměme nyní ale Bohumín. Uvážíme-li, kolik znečišťovatelů, ve kterých lokalitách, jakými mechanismy a v jakých časových okamžicích zneužívají ubohou Odru jako přírodní kanalizaci - pak je zřejmé, že i pro zkušené odborníky je nemožné znečištění jakkoliv modelovat. Třída jakosti je tedy i pro ně náhodná veličina a znečištění řeky náhodný jev.
Definice: Diskrétní náhodná veličina x je taková, která nabývá jen spočetně mnoha hodnot (pozn.: spočetné množiny jsou konečné i nekonečné!), každé obecně s jinou pravděpodobností (např. x = 0, 1, 2, ... nebo x = 1, 3, 5). Je-li tedy xÎX, je X spočetná množina.
Příklad: Diskrétní náhodná veličina je např. třída jakosti (I. až V.) povrchových vod podle ČSN 75 7221 a navazujících norem, konkrétně v profilu řeky Odry v Jakubčovicích. Může nabývat jen pěti hodnot, každé s obecně jinou pravděpodobností.
Na příkladě je možno ozřejmit fakt, že součet pravděpodobností výskytu hodnot diskrétní náhodné veličiny je roven jedné. Každá kvalita s jistotou zařazuje vodu právě do jedné z pěti tříd jakosti, a pravděpodobnost jistoty je právě jedna.
Definice: Spojitá náhodná veličina je taková, která nabývá nespočetně mnoha hodnot (pozn.: jakýkoliv interval reálných čísel obsahující alespoň dvě různé hodnoty je nespočetná množina). Je-li tedy xÎX, je X nespočetná množina.
Příklad: Spojitá náhodná veličina je např. obsah síranů podle ČSN 75 7221 a navazujících norem, konkrétně v profilu řeky Odry v Jakubčovicích. Může nabývat jakékoliv hodnoty větší nebo rovny nule a menší nebo rovny např. 100 (udává-li se v %).
Zákon rozdělení pravděpodobnosti náhodné veličiny x je zákon, který udává pravděpodobnost jevu, který lze touto veličinou popsat. Je číselně vyjádřen hodnotami funkce, která se nazývá hustota pravděpodobnosti. V dalším ji budeme označovat f(x), množinu možných hodnot veličiny x symbolem X.
Obecně se definuje hustota pravděpodobnosti náhodné veličiny jako
f(x) = p(a Ł x Ł b)
- tedy pravděpodobnost, že veličina x nabude hodnoty z intervalu <a,b> Ě X.
V návaznosti na hustotu pravděpodobnosti se zavádí distribuční funkce definovaná vztahem
F(b) = p(x Ł b)
- tedy pravděpodobnost, že náhodná veličina získá hodnotu nanejvýš b.
Pro diskrétní náhodné veličiny se nejčastěji klade a=b. Hustota pravděpodobnosti f(a) je tedy rovna
f(a) = p(x=a)
Distribuční funkce F(a) je rovna součtu pravděpodobností f(x) pro x Ł a a je tedy rovna
F(a) = S p(xi)
kde se sčítá přes všechna i, pro něž je xi Ł a.
Pro spojité náhodné veličiny platí mezi hustotou pravděpodobnosti f(x) a distribuční funkcí F(x) vztah
![]()
resp.
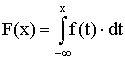
Příklad: Mějme dány pravděpodobnosti, že třída jakosti nějaké imaginární řeky v nějakém profilu nabude hodnoty T, následující tabulkou vycházející z dlouhodobého pozorování a měření:
| Třída jakosti T | 1 | 2 | 3 | 4 | 5 |
| Pravděpodobnost = hustota f(T) | 0,05 | 0,20 | 0,35 | 0,30 | 0,10 |
Tab. 2.1: Příklad hustoty pravděpodobnosti
Hustota pravděpodobnosti je tedy definována takto (jde o diskrétní funkci): f(1)=0,05; f(2)=0,20; f(3)=0,35; f(4)=0,30; f(5)=0,10. Hustota pravděpodobnosti jako funkce má i své grafické vyjádření, např. následujícím grafem:
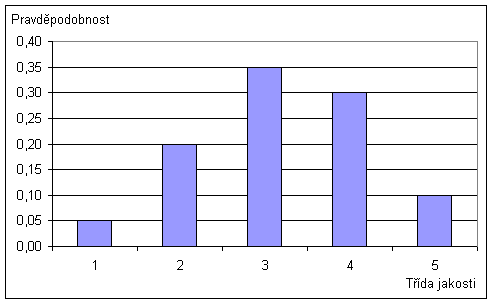
Obr. 2.1: Graf hustoty pravděpodobnosti
Obdobně distribuční funkce na týchž datech dá následující tabulku:
| Třída jakosti T | 1 | 2 | 3 | 4 | 5 |
| Hodnota distribuční funkce F(T) | 0,05 | 0,25 | 0,60 | 0,90 | 1,00 |
Tab. 2.2: Příklad hodnot distribuční funkce
a příslušný graf:
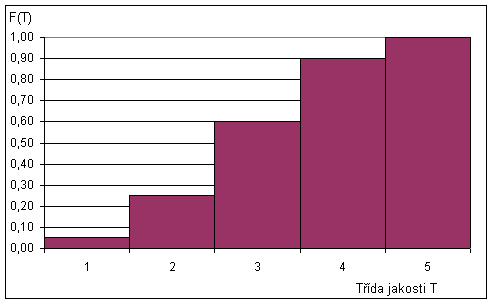
Obr. 2.2: Graf distribuční funkce
Hodnota vyjadřující střed, centrální tendenci, těžiště, průměrnou velikost apod. je definována jako střední hodnota:
Definice: Střední hodnota E(x) diskrétní
náhodné veličiny x je definována takto:
E(x) = S xi . p(xi)
kde se sčítá přes všechna i.
Příklad: Třídy jakosti ve shora uvedeném profilu hypotetické řeky mají střední hodnotu 1.0,05+2.0,20+3.0,35+4.0,30+5.0,10=3,20.
Definice: Střední hodnota E(x) spojité náhodné veličiny je definována takto:
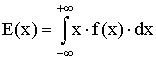
Hodnota, jistým způsobem vyjadřující rozptýlení, souhrnnou odchylku od střední hodnoty, je definována jako rozptyl:
Definice: Rozptyl D(x) diskrétní náhodné veličiny x je definován takto:
D(x) = S((xi - m)2 . pi) = ( S xi2 . pi ) - m2
kde symbolem m je označena střední hodnota E(x) a kde se sčítá přes všechna i.
Příklad: Třídy jakosti ve shora uvedeném profilu hypotetické řeky mají rozptyl 12.0,05+22.0,20+32.0,35+42.0,30+52.0,10-3,202=1,06.
Definice: Rozptyl D(x) spojité náhodné veličiny x je definován takto:
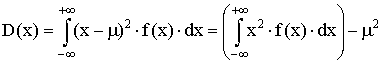
kde symbolem m je označena stejně jako v předchozím vztahu střední hodnota E(x).
Bezesporu nejdůležitějším rozdělením v teorii pravděpodobnosti a matematické statistice je normální rozdělení. Jeho význam udává např. centrální limitní věta, která za velmi obecných podmínek zaručuje, že součet nezávislých náhodných veličin má přibližně normální rozdělení bez ohledu na rozložení jednotlivých sčítanců. Další význam spočívá v tom, že jím lze aproximovat mnohá jiná rozdělení včetně diskrétních. Normální rozdělený bývá také nazýváno Gaussovým rozdělením a graf jeho hustoty Gaussovou křivkou.
Nejprve zaveďme normované normální rozdělení:
Definice: Normované normální rozdělení je takové, jehož hustota pravděpodobnosti (bývá zvykem ji označovat j(x) namísto obecného f(x)) má tvar
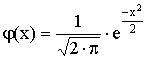
Lze ukázat, že střední hodnota normovaného normálního rozdělení je 0 a jeho rozptyl je 1. Graf hustoty je symetrický kolem nuly, funkce j má dva inflexní body {-1;+1}.
Distribuční funkce normovaného normálního rozdělení má tvar
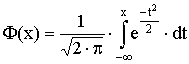
Obecně se pak zavádí normální rozdělení takto:
Definice: Normální rozdělení je takové, jehož hustota pravděpodobnosti f(x) má tvar
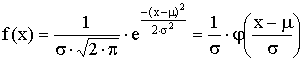
kde m je reálné číslo a s > 0. Graf hustoty f(x) je symetrický kolem přímky x=m , přičemž hodnota m je zároveň střední hodnotou. Funkce má dva inflexní body {m-s;m+s}, přičemž hodnota s je zároveň rozptylem.
Distribuční funkce obecného normálního rozdělení pak má tvar
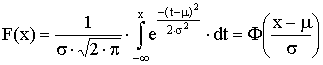
Příklad: Hustota pravděpodobnosti normálního rozdělení s m=3 a s=2 má graf
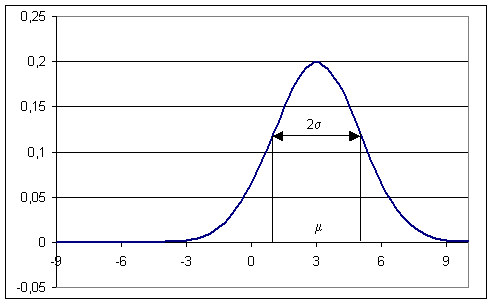
Obr. 2.3: Gaussova křivka