SQL a xBase v geostatistice a matematické geologii
Doc. Dr. Vladimír Homola, Ph.D.
Protože zvláště geologická a jim podobná data jsou převážně nazírána stochasticky, jsou základní statistické charakteristiky prvními informacemi o souboru požadované uživateli.
Jak počet, tak průměr jsou základními funkcemi dotazovacích jazyků. Tak např. výsledkem dotazu SQL tvaru
select count (HLOUBKA), avg (HLOUBKA) from VRTY
je počet vrtů a průměrná hloubka všech vrtů. Dotaz může obsahovat všechny další klauzule popsané v kapitole SQL shora, zvláště WHERE pro výběr jen z některých řádků. Stejný výsledek při otevřené tabulce VRTY dá následující příkaz xBase:
calculate cnt (HLOUBKA), avg (HLOUBKA)
který může být doplněn zvláště klauzulí FOR pro výběr jen z některých řádků.
Rovněž minimum a maximum jsou základními funkcemi dotazovacích jazyků. Tak např. výsledkem dotazu SQL tvaru
select min (HLOUBKA), max (HLOUBKA) from VRTY
je nejmenší a největší hloubka všech vrtů. Dotaz může obsahovat všechny další klauzule popsané v kapitole SQL shora, zvláště WHERE pro výběr jen z některých řádků. Stejný výsledek při otevřené tabulce VRTY dá následující příkaz xBase:
calculate min (HLOUBKA), max (HLOUBKA)
který může být doplněn zvláště klauzulí FOR pro výběr jen z některých řádků.
Rozptyl (disperze, variance) je nejvýznamnější charakteristika variability statistického souboru. Je nejen mírou variability ve smyslu rozptýlení kolem střední hodnoty, nýbrž i ve smyslu vzájemného rozptýlení hodnot. Obdobnou informaci podává směrodatná odchylka; ta má jako odmocnina z rozptylu tu výhodu, že vyjadřuje variabilitu v měrných jednotkách sledované veličiny.
Směrodatná odchylka je standardní funkcí pouze v xBase. Spočte ji např. příkaz tvaru
calculate std (HLOUBKA)
Protože rozptyl je kvadrátem směrodatné odchylky, lze k jeho výpočtu použít příkazu tvaru
calculate std (HLOUBKA) to STDODCH
s tím, že rozptyl je pak dán výrazem
STDODCH ^ 2
Pomocí dotazovacího jazyka SQL, který směrodatnou odchylku ani rozptyl standardně nedefinuje, je nutno se dotázat přímo definicí rozptylu jako průměrné kvadratické odchylky od průměru. Pro to je zapotřebí nejprve zjistit průměr:
select avg (HLOUBKA) from VRTY into array PRUMER
Pak je možno se dotázat na rozptyl:
select avg ( (HLOUBKA - PRUMER(1))^2 )
a na směrodatnou odchylku:
select sqrt (avg ( (HLOUBKA - PRUMER(1))^2 ))
Všechny dotazy jsou opět uvedeny v nejjednodušším tvaru; lze je rozšiřovat o všechny definované klauzule.
Základní tabulku např. pro grafické znázornění absolutních a relativních četností vytvoří následující dotaz:
select HLOUBKA, count (HLOUBKA) as CETNOST
from VRTY
into table TABFREKV
group by HLOUBKA
order by HLOUBKA
Takto vytvořená tabulka může být přímo otevřena populárními tabulkovými procesory jako Excel, Lotus nebo Quattro pro grafické zpracování četností.
Přímý dotaz na tyto základní neparametrické charakteristiky, tolik potřebné v geo- praxi, není prostředky dotazovacích jazyků možný (neexistuje standardní funkce obdobná např. AVG z SQL). Neelegantní, avšak nejjednodušší je zřejmě dotaz na setříděné pole předmětné veličiny a pak "ruční odpočítání" hodnoty uprostřed resp. v první a třetí čtvrtině:
select HLOUBKA from VRTY into cursor DATA order by HLOUBKA
Většina systémů tento dotaz umístí do prohlížecího okna opatřeného indikátorem čísla aktuálního řádku a celkového počtu řádků. Proto zjištění požadovaných řádků není příliš obtížné.
Pro výpočet mediánu pro lichý počet dat lze použít i následujícího obratu (_tally je identifikátor obsahující počet vybraných řádků příkazem SELECT):
select HLOUBKA from VRTY into array DATA order by HLOUBKA
s tím, že medián je pak dán hodnou výrazu
DATA [ _tally / 2 ]
a např. dolní kvartil hodnotou
DATA [ _tally / 4 ]
ovšem pouze pro _tally skutečně "čtvrtící" soubor dat.
Hodnoty semivariancí jako základního nástroje pro strukturní analýzu lze získat poměrně jednoduše - rozhodně pracnost při sestavení dotazu je zcela zanedbatelná oproti ručnímu vyhodnocování.
Výborně se zde hodí právě vlastnost dotazu SELECT při práci s více tabulkami najednou: do výběru kombinuje ze všech vstupů stylem "každý s každým".
Výsledkem dotazu je relační databáze, která může sloužit jako přímý vstup pro zobrazení experimentálního semivariogramu např. programy Excel, Lotus, Quattro apod.
Sestavení dotazu popíšeme nyní podrobněji, protože právě na tomto příkladu lze dokreslit sílu nástrojů pro zpracování databází.
Nejprve jednoduchý případ: mějme v relační databázi VSTUP přímo připravená data; ve sloupci XX a YY souřadnice v terénu, ve sloupci ZZ hodnoty sledované veličiny. Hodnoty SMVAR semivariance s krokem označeným HH umístí do relační databáze VÝSTUP následující dotaz:
select
HH*round (sqrt ( (A.XX-B.XX)^2 + (A.YY-B.YY)^2 ) / HH,0) as VZD,
avg ((A.ZZ-B.ZZ)^2)/2 as SMVAR
from (VSTUP) A, (VSTUP) B
into table (VYSTUP)
where not (A.XX = B.XX and A.YY = B.YY and A.ZZ = B.ZZ)
group by VZD
order by VZD
Dotaz především používá vstupního souboru dvakrát; pro výstup se tedy zpracují všechny kombinace všech bodů vstupu. Podmínka v klauzuli WHERE však zajistí, že se tak nezpracuje kombinace bodu se sebou samým.
První sloupec výstupní databáze obsahuje třídy vzájemných vzdáleností tak, jak to požaduje definice semivariance. Pythagorovou větou se zjistí vzájemná vzdálenost dvou bodů, zaokrouhlení podílu této vzdálenosti a zvoleného kroku dá hodnotu, kolikrát je vzdálenost větší než zvolený krok, a konečně vynásobením zvoleným krokem se získá přímá hodnota středu třídy.
Semivariance je pak polovina průměrné kvadratické odchylky sledovaných hodnot v jednotlivých třídách. Tvoří druhý sloupec výstupní databáze. Stejné hodnoty středů tříd jsou prvkem, které řídí seskupování (group by) do skupin, ve kterých se průměrování provádí. A konečně je výsledná databáze setříděna (order by) podle hodnot středů tříd.
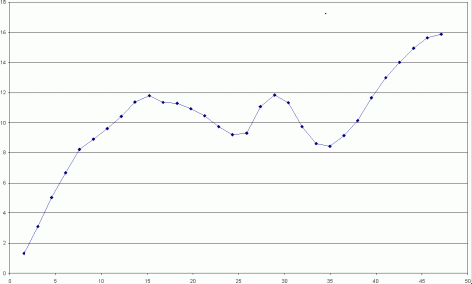
Výsledná databáze může být přímo zpracována do grafického tvaru (semivariogramu) vhodným programem. Uvedeným dotazem byla vytvořena tabulka semivariancí hodnot zinku získaných z vertikálního vrtu s krokem 52 [m]. Tabulku vykreslil program Excel následovně:
Obrázek 1: Semivariogram zinku
V tomto případě šlo o lineární strukturu, proto hodnoty XX byly hloubkové údaje, hodnoty YY byly všechny rovny nule.
Semigrafický výstup lze umístit přímo do relační databáze jako histogram. Stačí do výstupní databáze umístit další (textový) sloupec o nějaké vhodné šířce (např. 50 znaků), vytvořit databázi dotazem
select
HH*round (sqrt ( (A.XX-B.XX)^2 + (A.YY-B.YY)^2 ) / HH,0) as VZD,
avg ((A.ZZ-B.ZZ)^2)/2 as SMVAR,
space (50) as GRAF
from (VSTUP) A, (VSTUP) B
into table (VYSTUP)
where not (A.XX = B.XX and A.YY = B.YY and A.ZZ = B.ZZ)
group by VZD
order by VZD
poté zjistit maximální hodnotu semivariance
calculate max (SMVAR) to MAXSVG
a nakonec naplnit sloupec pro graf
replace all GRAF with replicate (chr (176), 50*SVGRAM/MAXSVG)
Dále lze ve shora uvedeném dotazu modifikovat klauzuli WHERE podmínkou pro úhel směrového vektoru daného dvojicí bodů. Výsledkem je směrování semivariogramů s konečným cílem - elipsou anizotropie.
Velmi populární je v nejrůznějších geostatistických programech topografické a prostorové zobrazení lokálních odhadů sledované veličiny na nějaké zájmové ploše. Základem jsou obecně známé matematické postupy; z nich ukážeme realizaci metody nazývaní Inverse Distance Method (metoda inverzní vzdálenosti).
Metoda zjistí lokální odhad v místě o souřadnicích [x0,y0] jako vážený průměr všech daných hodnot, kde váhami jsou reciproké hodnoty vzdáleností jednotlivých zadaných bodů od místa [x0,y0].
Nejprve bodový odhad. Mějme tabulku (naměřených) hodnot; použijeme tabulku s výsledky geochemických analýz vzorků půd se jménem PŮDY z oblasti Ostravy, kde [x,y] jsou souřadnice místa odběru, (z) je analyzovaná hodnota. Dotaz tvaru
select
sum (z / sqrt ( (x0-x)^2 + (y0-y)^2 )),
sum (1 / sqrt ((x0-x)^2 + (y0-y)^2 ))
from PUDY
into array SM
zjistí potřebné součty, takže lokální odhad v [x0,y0] je dán výrazem
SM [1] / SM [2]
Základem zobrazovací části zmíněných programů je dopočet lokálních odhadů do uzlů obdélníkové sítě pokrývající zájmový terén, a následné zobrazení hodnot v uzlech prostorově jako známý "drátěný model" nebo topograficky interpolací na úsečkách sítě.
Topografické, ale zvláště prostorové zobrazení hodnot v obdélníkové síti dnes zvládne téměř každý kvalitnější program. Obrázek v této kapitole byl připraven programem Excel. Pokud tedy jde pouze o tuto úlohu, netřeba kupovat náročné a drahé - byť komplexní - programy; lze použít postupu naznačeného dále.
V tomto příkladu je modelována plocha lokálních odhadů na kilometrové síti s jihozápadním rohem [470,1190] a severovýchodním rohem [490,1210].
Nejprve se vytvoří tabulka, obsahující souřadnice všech uzlů sítě:
create table tabuzlu (x n(4), y n(4))
for ii=470 to 490
for jj=1190 to 1210
insert into tabuzlu values (ii, jj)
endfor
endfor
Dále se využije vlastnost dotazu SELECT při práci s více tabulkami najednou: do výběru kombinuje ze všech vstupů stylem "každý s každým". Vytvoří se tabulka kombinací všech uzlů se všemi zadanými daty:
select
TABUZLU.x as x0,
TABUZLU.y as y0,
PUDY.x as xi,
PUDY.y as yi,
PUDY.z as z
from TABUZLU, PUDY
into table TABKOMB
Konečně tabulku lokálních odhadů v uzlech sítě vytvoří dotaz
select
x0, y0,
9999999999.99999 as ODHAD,
sum (z / sqrt ((x0-xi)^2 + (y0-yi)^2 )) as SumM,
sum (1 / sqrt ( (x0-xi)^2 +(y0-yi)^2 )) as SumR
from TABKOMB
into table TABODH
group by x0, y0
order by x0, y0
s připraveným čitatelem a jmenovatelem zlomku udávající odhad; ten se dopočte jednorázově např. příkazem
replace all ODHAD with SumM/SumR
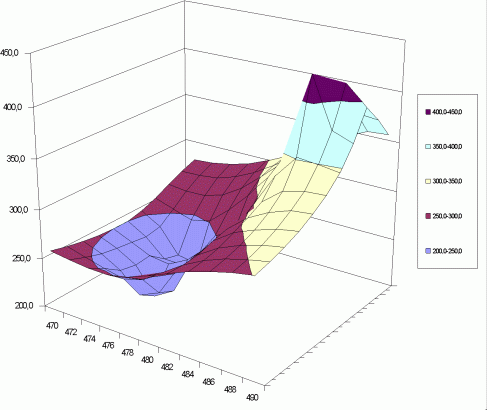
Obrázek 2: Prostorový model
Tabulka odhadů TABODH je běžná relační databáze, která svými položkami x0, y0 a ODHAD může být vstupem zmíněných obecných programů, např. Excelu ap. Právě tak byl vykreslen předchozí obrázek.
Rev. 7 / 2010