VYSOKÁ ŠKOLA BÁŇSKÁ - TECHNICKÁ UNIVERZITA OSTRAVA
Základy programování
Doprovodný text pro distanční výuku předmětu Programování
Za vydatné pomoci publikace doc. Ing. Michala Brandejse, CSc. volně sestavil doc. Dr. Vladimír Homola, Ph.D.
Ostrava 2021
Aby tento text mohl vzniknout z urychlené potřeby doplnění výuky
předmětu „Programování“ v režimu distančního vyučování, byla díky laskavosti
pana docenta Ing. Michala Brandejse, CSc. velmi hojně využita
jeho publikace Procesory Intel Pentium, uvedena níže na čestném prvním místě v
seznamu literatury. Pan docent Brandejs oprávněně požaduje (a my to zde s radostí
plníme) uveřejnění této copyrightové doložky:
Tento text byl vydán v nakladatelství Grada v roce 1994. Po vypršení platnosti
nakladatelské smlouvy byl text autorem jako další vydání elektronicky zveřejněn dne
1. 9. 2010. Text lze šířit výhradně bezplatně a s uvedením autora a této copyrightové
doložky. Text lze libovolně citovat, pokud je uveden odkaz na zdroj následovně:
Brandejs, M. Mikroprocesory Intel – Pentium [online]. Brno : Fakulta informatiky,
Masarykova univerzita, 2010. Dostupný z WWW:
http://www.fi.muni.cz/usr/brandejs/Brandejs_Mikroprocesory_Intel_Pentium_2010.pdf
Rovněž vzhledem k firmě Intel je nutno uvést toto:
The following are trademarks of Intel Corporation and may only be used to identify Intel
products: Intel, Intel287, Intel386, Intel387, Intel486, Intel487, Pentium.
Úvod - předpokládané znalosti
U posluchačů se předpokládají dobré znalosti těchto pojmů: bit, byte, zápis čísel ve dvojkové soustavě a operace s nimi, zápis čísel v šestnáctkové soustavě a operace s nimi, little Endians, big Endians. Protože však tyto výukové texty slouží nejen pro informatické obory, jsou právě vyjmenované pojmy detailně rozvedeny v úvodní části tohoto textu.
Pozn.: Nejde o znalosti hardwarové konstrukce uvedených pojmů, ale o aplikaci jejich logického zevšeobecnění. Je ovšem pravdou, že alespoň minimální představa o fyzické realizaci (např. bit: klopný obvod, feromagnetická doména, odrazivé místo povrchu CD apod.) mnohdy podpoří zamýšlený výukový cíl.
Celý tento text se týká výhradně 32bitových procesorů Intel a jejich klonů, a systémových prostředí Microsoft bázovaného Disk Operating System (DOS) s grafickou nadstavbou Graphical User Interface (GUI).
Vývojová řada procesorů
Zrod 32bitového mikroprocesoru Intel386 se datuje rokem 1985. Má tři pracovní režimy: reálný, chráněný a virtuální 8086. V reálném režimu je procesor, stejně jako 80286, slučitelný s 8086, i když můžeme používat 32bitové prostředí. V chráněném režimu procesor pracuje jako plně 32bitový a poskytuje všechny své vlastnosti. Tento režim opět není slučitelný s 8086. Dostupná kapacita fyzické paměti je 4 GB a virtuální paměti 64 TB. Režim virtuální 8086 lze zapnout v rámci chráněného režimu procesoru pro konkrétní úlohy. Úloha, která je zpracovávána jako „virtuální 8086“, se v prostředí chráněného režimu chová tak, jako by byla řešena procesorem 8086 s většinou jeho vlastností. Procesor Intel386 spolupracuje buď s koprocesorem Intel387, nebo Intel287. Procesor Intel386 SX je 32bitový procesor pro 16bitové vnější prostředí.
Rok 1989 přinesl typ lišící se od předchozích pokročilejší výrobní technologií. Procesor Intel486 (nebo stejný název je Intel486 DX) je programově slučitelný s procesorem Intel386. Liší se pouze výkonem (je 3 až 5krát rychlejší) a na čipu má integrovánu rovněž jednotku operací v pohyblivé řádové čárce (FPU) a rychlou vyrovnávací paměť (Cache). Varianta Intel486 SX nemá na čipu funkční FPU. Varianta Intel486 DX2 pracuje vnitřně na dvojnásobné frekvenci proti frekvenci okolí procesoru (např. udávaná frekvence 66 MHz zpravidla znamená, že na této frekvenci procesor pracuje uvnitř, okolí pracuje na frekvenci 33 MHz).
Procesor Pentium je od roku 1993 novým procesorem firmy Intel z řady procesorů 86. Je 100% binárně kompatibilní s předchozími typy procesorů 8086/88, 80286, Intel386 DX, Intel386 SX, Intel486 DX, Intel486 SX a Intel486 DX2. Díky kompatibilitě zdola bylo možné zahrnout do textu i poznámky k předchůdcům ve výše uvedené řadě.
V současné době převládají v nových sestavách 64bitové procesory, poprvé uvedenými v první polovině roku 2001 modelem Itanium. Dnes vidíme v provozu celou škálo od starších dvoujádrových po novější šestijádrové (např. řady Intel Core i5-9600). V 64bitovém režimu jsou použity strojové instrukce, které pracují se 64bitovou adresou, takže je teoreticky možné využívat až 264 bajtů operační paměti RAM, avšak reálně procesor podporuje 248 bajtů = 256 TB.
Kvůli prodloužení operandů strojových instrukcí z 32bitových na 64bitové došlo k tzv. zřídnutí kódu (stejný strojový kód je v 64bitové variantě delší, než v 32bitové), a proto jsou nároky na dostupnou operační paměť u 64bitového systému vyšší, než kdyby byl použit stejný 32bitový operační systém (v systému Windows 7/10 jsou minimální požadavky 1 GB pro 32bitový systém a 2 GB RAM pro 64bitový systém).
Základní rozšíření 64bitových procesorů:
Kvůli zpětné kompatibilitě je rozšíření realizováno jako další režimy procesoru. K reálnému, chráněnému a V86 režimu i386, nyní zvanými „Legacy“ (zděděný) režim, přibyly dva „Long“ (dlouhé) režimy: 64bitový a kompatibilní. Procesor je možné provozovat buď s 32bitovým jádrem operačního systému (kterým může být i systém určený pro i386) v Legacy režimech, nebo s 64bitovým jádrem v Long režimu – jádro potom běží v 64bitovém režimu a aplikace v 64bitovém nebo v kompatibilním režimu.
Většina vylepšení architektury se týká pouze 64bitového režimu, menšina i kompatibilního. Legacy režimy nemají žádné vylepšení (na rozdíl od i386, kde byl vylepšen i starý reálný režim).
- Plná podpora 64bitových celých čísel – veškeré aritmetické i logické operace se provádí v 64 bitech.
- Rozšíření registrů – registry byly rozšířeny na 64 bitů (stále je přístupná 32bitová, 16bitová a 8bitová část).
- Rozšíření počtu registrů – k původní sadě 8 'general-purpose' registrů přibylo dalších 8. To umožňuje držet více lokálních proměnných v registrech a tedy významně zrychluje aplikace. 16 registrů je ovšem stále málo v porovnání s RISCovými stroji.
- Zdvojnásoben z 8 na 16 byl i počet XMM registrů.
- Rozšíření virtuálního adresového prostoru – současné implementace mohou adresovat 256 TB, v budoucnu bude možné rozšířit na 16 EiB. Pointerová aritmetika běží v 64 bitech, omezení je dáno metodou překladu virtuálních adres na fyzické.
- Rozšíření fyzického adresového prostoru – původní implementace mohla adresovat maximálně 1 TB RAM; od roku 2007 je používáno 48 bitů, což je adresace maximálně 256 TB; architektura umožňuje rozšíření až na 4 PB. V legacy režimech je podporováno PAE (rozšíření fyzických adres), stejně jako na moderních procesorech architektury i386, umožňující přístup k 64 GB.
- Adresace relativní k ukazateli instrukce – adresace relativní k RIP zvyšuje efektivitu kódu nezávislého na pozici používaného ve sdílených knihovnách.
- SSE instrukce – součástí architektury je povinná implementace rozšíření procesorů i386 SSE a SSE2 pro výpočty v pohyblivé řádové čárce. Podpora SSE3 byla přidána dodatečně.
- No-eXecute bit – stránku paměti je bitem NX možné označit jako obsahující pouze data a zabránit tak spuštění kódu z dané stránky. Tato vlastnost umožňuje chránit systém před většinou buffer overrun (přetečení bufferu) chyb, které často zneužívá k útoku malware.
- Odstranění starších vlastností – v Long režimu procesor nepodporuje některé méně používané vlastnosti i386, jako je segmentace paměti (částečně stále fungují registry FS a GS), TSS nebo v86.
Tyto textu jsou založeny na popisu 32bitového procesoru Pentium především pro relativní komplexnost běžně dostupných technických informací. Bez újmy na obecnosti lze informace v něm aplikovat i na 64bitové procesory (s přihlédnutím k 64bitovým rozšířením uvedeným shora).
Binární minimum
Terminologie
Základní pojmy níže uvedené jsou částečně vybrány a volně citovány z normy ISO 2382 (poměrně dobře jí odpovídá dřívější ČSN 36 9001).
Bit (z anglického binary digit - dvojková cifra, zkratka b): cokoliv, co nabývá pouze dvou hodnot a „počítač“ je schopen rozeznat, kterých. Příklad: zrnko materiálu je nebo není zmagnetované; tranzistor proud vede nebo nevede; žárovka svítí nebo nesvítí. Protože tyto dvě hodnoty jsou protikladné, bez ohledu na fyzikální podstatu se chápou jako NEPRAVDA a PRAVDA, NE a ANO apod. V těchto učebních textech však budou používány ve svém původním významu, tj. jako cifry 0 a 1 dvojkové soustavy. Aby nedošlo k záměně s běžně používanou soustavou desítkovou, používá se někdy i symbolů O a I.
Byte (kdysi překládáno jako slabika, dnes se „bajt“ většinou vůbec nepřekládá, zkratka B): posloupnost osmi bitů = dvojkových cifer. Jsou-li bity vyjádřeny jako 0 a 1, pak je jeden byte uspořádanou osmicí nul a jedniček a tvoří tedy poziční zápis osmiciferného čísla ve dvojkové soustavě. Těchto (různých) osmic je 256, počínaje např. 00000000, pak 00000001, ..., až po 11111110 a 11111111. Dvojková čísla zde uvedená (ve dvojkové soustavě) odpovídají následujícím číslům (v desítkové soustavě): 0, 1, ..., 254, 255. Graficky je možno jeden byte znázornit např. takto:
| Byte: | ||||||||
| Obsah | O | O | O | I | O | O | I | O |
| bitu č. | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Právě z důvodu logického nazírání na bit jako dvojkovou cifru - a na byte jako poziční zápis číselné hodnoty ve dvojkové soustavě - mají bity v rámci bytu svoji adresu (jsou „očíslované“), která odpovídá příslušné mocnině základu soustavy, zde tedy mocnině 2.
Paměť: Uspořádaná množina bytů přístupná výpočetnímu systému. Fyzická realizace je různá: uspořádání ve formě diskety, pevného disku, magnetické pásky, integrovaného obvodu apod. Bez ohledu na fyzickou realizaci jsou paměti nazírány jako linearizovaná (a tedy „očíslovatelná“) posloupnost bytů. Očíslování bývá provedeno počínaje nulou, tato „pořadová“ čísla se nazývají adresy jednotlivých bytů. Na paměť je tedy možno pohlížet např. takto:
| Paměť: | ||||||||
| Obsah | OIIOIOIOO | OIIOIOIOI | OOIIIIIO | OIIOIOII | OIIIIOOIO | OIIIOOIO | IIIOOOOOI | ... |
| bytu s adresou: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... |
Poznámka: Z hlediska procesoru je byte nejmenší adresovatelná jednotka paměti. Problém však nastává při adresaci více bytů „vedle sebe“, které mají tvořit logický celek (např. celé číslo na více bytech). K tomu viz pojem Endians vysvětlený níže.
Kilobyte, Megabyte, Gigabyte, Terabyte a další: předpony pro udávání velikosti paměti (tisíc, milion, miliarda, bilion bytů).
Poznámka 1: V občanském životě je např. předpona kilo- spojena s hodnotou přesně 1000. Ve dvojkovém počítačovém prostředí se však lépe pracuje s hodnotou 1024, protože ta je rovna 210, tedy dvojkově 1 a deset nul. Pro rozlišení se „občanské“ předpony zapisují malými písmeny, kdežto „počítačové“ velkými. „Občanským“ se říká „malé kilo“ atd, kdežto „počítačovým“ se říká „velké kilo“; analogicky ostatní jednotky. Je tedy kB, mB, gB a tB přesně tisíc, milion, miliarda a bilion bytů, kdežto KB, MB, GB a TB je 1 024, 1 048 576, 1 073 741 824 a 1 099 511 627 776 bytů, což je 210, 220, 230 a 240 bytů.
Poznámka 2: Autor si je vědom toho, že někdy kolem roku 2004 byla převzata norma u nás označovaná jako ČSN-IEC-60027-2, která ponechává „malým“ jednotkám jejich původní název a označení (tedy např. kilobyte = kB), kdežto pro „velké“ jednotky zavádí názvy „kibibyte“, „mebibyte“, „gibibyte“ atd. a označení KiB, MiB, GiB atd. - viz také [5]. Autor však přísahá, že s tímto označováním se kromě Wikipedie a zmíněné normy v praktickém životě nesetkal.
Datový typ: způsob chápání obsahu jednoho, dvou nebo více po sobě následujících bytů v paměti.
Semilogaritmický zápis čísla je zápis číselné hodnoty ve tvaru součinu celého nebo necelého čísla M a mocniny základu E (např. 10) - známý např. z kalkulaček, tj. ve tvaru M x zE, např. 1,2 x 103 (=1200). Část M je nazývána mantisa, část E je nazývána exponent.
Normovaný semilogaritmický zápis čísla: Každou nenulovou hodnotu lze zapsat pomocí semilogaritmického zápisu tak, že celá část mantisy má jedinou, a to nenulovou cifru (stačí příslušně upravit exponent) - např. 123.456 x 1020 = 1.23456 x 1022. Takovému zápisu se říká normovaný a jeho analogie ve dvojkové soustavě se využívá při ukládání neceločíselných hodnot v paměti.
Ekvivalentní definice normovaného semilogaritmického zápisu čísla: Každou nenulovou hodnotu lze zapsat pomocí semilogaritmického zápisu tak, že celá část mantisy má jedinou, a to nulovou cifru, a první cifra za oddělovačem celé a necelé části je nenula (stačí příslušně upravit exponent) - např. 123.456 x 1020 = 0.123456 x 1023. Tato ekvivalentní definice je užita např. v procesorech Intel při implementaci neceločíselné hodnoty v jednoduché nebo dvojnásobné přesnosti.
Soustavy o základu 2, 10, 16
Binární (= dvojková) soustava definuje takový poziční zápis číselných hodnot, při kterém je jako základ soustavy použita hodnota 2. Hexadecimální (= šestnáctková) soustava definuje takový poziční zápis číselných hodnot, při kterém je jako základ soustavy použita hodnota 16. Minimální informace o těchto soustavách podejme na základě analogie s běžně používanou soustavou dekadickou (= desítkovou). Připomeňme jen trochu pozapomínanou skutečnost, že zápis čísla (v jakékoliv soustavě) slouží k vyjádření počtu nějakých jednotek resp. jejich částí.
Desítková soustava
Dekadická (= desítková) soustava používá takový poziční zápis číselných hodnot, při kterém je jako základ použita hodnota 10. Zopakujme, proč je 348 rovno právě 348: je to proto, že tato hodnota obsahuje 3 stovky (stovka = 102), 4 desítky (desítka = 101) a 8 jednotek (jednotka = 100). Zapsáno jinak:
| 102 (= 100) | 101 (= 10) | 100 (= 1) | celkem | |||
| x 3 | + | x 4 | + | x 8 | = | 348 |
Nyní rozšiřme opakování o to, proč je 348,65 rovno právě 348,65:
| 102 (= 100) | 101 (= 10) | 100 (= 1) | 10-1 (= 0,1) | 10-2 (= 0,01) | celkem | |||||
| x 3 | + | x 4 | + | x 8 | + | x 6 | + | x 5 | = | 348.65 |
Podotkněme jen, že správně by všechna čísla v tomto odstavci zapisovaná měla být důsledně označena základem své soustavy; místo 348 by tedy mělo být lépe zapsáno 34810. Zatím však byla použita jen desítková soustava a tedy se „to nepletlo“.
Poslední připomenutí: v zápise čísel může být právě tolik různých hodnot daného řádu, kolik je základ soustavy. To znamená např. žádnou stovku, jednu stovku, dvě stovky, ..., osm stovek nebo devět stovek. Deset stovek už ne, protože to by byla jedna tisícovka („přechod přes řád“). Pro znázornění těchto deseti různých hodnot je zapotřebí deseti jakýchkoliv, ale různých symbolů. V našich končinách a našem věku bývá zvykem používat symboly 0, 1, 2, ..., 8 a 9.
Dvojková soustava
Jde o poziční číselnou soustavu se základem 2. Analogii s desítkovou soustavou začněme „od konce“: v zápise čísel může být právě tolik různých hodnot daného řádu, kolik je základ soustavy (tj. dvě). To znamená např. žádnou dvojku nebo jednu dvojku; dvě dvojky už ne, protože to by byl „přechod přes řád“. Pro vyjádření těchto dvou různých hodnot je zapotřebí dvou různých symbolů. Bývá zvykem používat symboly 0 nebo O (pro počet žádný) a 1 nebo I (pro počet jeden).
Každý zápis číselné hodnoty ve dvojkové soustavě proto může obsahovat pouze symboly 0 a 1. Je tedy např. 1001 jistě zápis číselné hodnoty ve dvojkové soustavě. Aby bylo zcela jasné, že jde o zápis právě ve dvojkové soustavě, zapisuje se v nejednoznačných případech hodnota jako 10012 nebo IOOI2 na rozdíl např. od 100110.
Protože většina z nás je zvyklá chápat počty vyjádřené zápisem čísla jen v desítkové soustavě, vysvětlíme způsob převodu zápisu nějaké (např. uvedené 1001) číselné hodnoty ze dvojkové do desítkové soustavy. Je analogicky jako shora
| 23 = 810 | 22 = 410 | 21 = 210 | 20 = 110 | celkem | ||||
| x 1 | + | x 0 | + | x 0 | + | x 1 | = | 910 |
Obdobně zápis necelého čísla - nejde dost dobře říci ani „desetinného“ čísla ani čísla s „desetinnou částí“ - např. 1001,0112:
| Celá část |
, |
„Necelá“ část | celkem | |||||||||||
| 23 = 810 | 22 = 410 | 21 = 210 | 20 = 110 | 2-1 = 1/210 = 0,510 | 2-2 = 1/410 = 0,2510 | 2-3 = 1/810 = 0,12510 | ||||||||
| x 1 | + | x 0 | + | x 0 | + | x 1 | + | x 0 | + | x 1 | + | x 1 | ||
| 8 | + | 0 | + | 0 | + | 1 | + | 0 | + | 0,25 | + | 0,125 | = | 9,37510 |
Opačný převod - tj. převod zápisu nějaké číselné hodnoty ze soustavy desítkové do soustavy dvojkové - spočívá v postupném zkoumání, kolikrát se v čísle vyskytují jednotlivé mocniny dvou. Ukažme tento postup např. pro číselnou hodnotu 1910:
-
Nejnižší mocnina dvou, která se v 1910 už nevyskytuje, je pátá: 25 = 3210. Začneme tedy čtvrtou mocninou:
-
Čtvrtá mocnina 2 (24 = 16) se v 19 vyskytuje 1krát a zbude 310.
-
Třetí mocnina 2 (23 = 8) se v 3 vyskytuje 0krát a zbude 310.
-
Druhá mocnina 2 (22 = 4) se v 3 vyskytuje 0krát a zbude 310.
-
První mocnina 2 (21 = 2) se v 3 vyskytuje 1krát a zbude 110.
-
Nultá mocnina 2 (20 = 1) se v 1 vyskytuje 1krát a zbude 0.
Hodnota 1910 je tedy rovna 100112.
S ohledem na probíranou problematiku ještě jedna poznámka: obsah jednoho bytu může být interpretován jako zápis právě osmiciferného dvojkového čísla. Nejmenší číselná hodnota je osm nul, tedy nula. Největší číselná hodnota je osm jedniček. Postup uvedený shora dává pro hodnotu 111111112 desítkový ekvivalent
111111112 = 27 + 26 + 25 + 24 + 23 + 22 + 21 + 20 = 128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 = 25510
Všech různých obsahů jednoho bytu je tedy 256.
Šestnáctková soustava
Jde o poziční číselnou soustavu se základem 16. Pro zápis číselné hodnoty v této soustavě musí tedy být k disposici 16 různých symbolů, označujících počty nula, jedna ... až patnáct. Ve shodě s teorií čísel se tyto symboly nazývají cifry a celá současná počítačová civilizace používá následující:
| Cifry šestnáctkové soustavy | ||||||||||||||||
| Symbol | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| Počet | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
Způsob převodu zápisu hodnoty v šestnáctkové soustavě do soustavy desítkové je zcela analogický předchozímu odstavci - jediný rozdíl je v základu, který je nyní 16. Ukažme to na příkladu hodnoty 2AF316 (značí A počet 10 a F počet 15 - viz předchozí tabulka):
| 163 = 409610 | 162 = 25610 | 161 = 1610 | 160 = 110 | celkem | ||||
| x 2 | + | x 10 | + | x 15 | + | x 3 | = | 10 99510 |
Šestnáctková soustava je nejčastěji používanou soustavou v počítačovém a vůbec digitálním světě. Velmi usnadňuje a zpřehledňuje zápis stavů paměťových elementů, které jsou fyzikálně tvořeny dvoustavovými konstrukčními prvky (generalizovanými jako bity). Platí totiž toto: cifry šestnáctkové soustavy označují počty 0 až 15 podle definice. Ovšem počty 0 až 15 jsou rovněž všemi hodnotami, které tvoří kombinace různých hodnot v zápisu 4bitového čísla: od 00002 = 010 do 11112 = 8 + 4 + 2 + 1 = 1510. Je-li tedy např. obsah jednoho bytu chápaný jako osmiciferné dvojkové číslo, pak hodnota v něm uložená lze zapsat právě 2 ciframi šestnáctkové soustavy:
| Byte: | |||||||||
| Obsah | I | O | I | O | O | I | I | O | |
| šestnáctkově. | A | 6 | |||||||
Zápis hodnot jednotlivých bytů je nejčastějším použitím šestnáctkové soustavy. Zatímco ve dvojkové je zapotřebí 8 cifer, v šestnáctkové jen 2 - a to je daleko přehlednější. Místo intervalu hodnot uchovatelných v jednom bytu zapsaných ve dvojkové soustavě <00000000; 11111111> je jistě zápis v šestnáctkové soustavě <00; FF> příjemnější. Z tohoto příkladu jeden důležitý závěr: protože F je nejvyšší cifrou šestnáctkové soustavy, je FF největší dvoucifernou hodnotou zapsanou v šestnáctkové soustavě. Je přitom FF16 = 15 x 16 + 15 x 1 = 15 x 17 = 25510.
Známým příkladem použití zápisu hodnoty v šestnáctkové soustavě je kódování barev v HTML souborech: parametr color = #RRGGBB určuje barvu jako trojici intenzit základních barev (po řadě R = red = červená, G = green = zelená, B = blue = modrá), každá ve stupních intenzit od 0 do 255, zapsaných jako šestnáctkové číslo. Tedy kód #FF00FF znamená: červená složka naplno, zelená není, modrá naplno - dohromady tedy barva fialová (magenta).
Endians
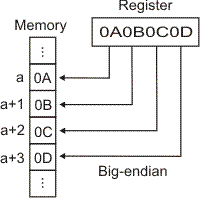
Tento etymologicky zajímavý pojem použitý již Johnatanem Swiftem je mezi počítačovou veřejností znám spíše ve spojení Little-endian a Big-endian.
Jde o následující problém: Celý tento článek mluví o několika bytech umístěných v paměti „vedle sebe“. Ony byty však mají konkrétní adresy. Mluvíme-li např. o 2-bytové hodnotě 910 = 10012 typu Unsigned Short Integer = 0000 0000 0000 10012, jak je tato hodnota umístěna v paměti třeba od adresy 13? Takto
| Big-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 0 0 0 0 | 0 0 0 0 I 0 0 I | . . . |
| na adrese | 12 | 13 | 14 | 15 |
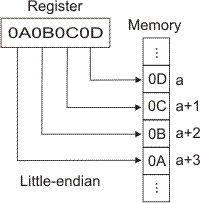
nebo takto:
| Little-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 I 0 0 I | 0 0 0 0 0 0 0 0 | . . . |
| na adrese | 12 | 13 | 14 | 15 |
jinak řečeno, je první umístěný byte ten nejvíce či nejméně významný? Je dobré si v tomto případě uvědomit, že druhý uvedený případ je ekvivalentní tomuto:
| Little-Endian | ||||
| Obsah bytu | . . . | 0 0 0 0 0 0 0 0 | 0 0 0 0 I 0 0 I | . . . |
| na adrese | 15 | 14 | 13 | 12 |
tj. jenom „kreslíme“ adresaci paměti opačně než v prvním případě. Ve všech třech případech už jsou nad schématy uvedena označení pomocí „endian“. Toto není jen otázka umístění vícebytových dat v paměti. Například při přenosu dat USB (= sériovým) portem je nejdříve z každého bytu vysílán bit 7 nebo bit 0? Uvědomme si dále, že i v hovorové řeči používáme např. dvacátý první (=Big-endian) nebo jedenadvacátý (=Little-endian).
Registry procesorů Intel jsou tvořeny řadou bitů s nejvyšším bitem vlevo (detailněji viz níže). Při přenosu z a do paměti pak rozdíl mezi Little-endian a Big-endian pěkně znázorňují schémata uvedená v [4]:
 |
 |
Procesory Intel a programovací jazyky a systémy minimálně Microsoftu používají Little-endian. Celá řada operačních systémů pracujících na procesorech x86 a x86-64 používá Little-endian, stejně tak řada jiných systémů pracujících např. na procesorech SPARC, Motorola a dalších používá Big-endian.
Poznámka: Tohle pořádně zmate chudáka programátora, který se pokusí např. svým způsobem zpracovat soubory formátu shape-files renomované firmy ESRI zabývající se dnes velmi žádanou oblastí mapových serverů. V jediném souboru tohoto formátu, v jediném jeho záznamu (= řádku) totiž lze nalézt jak některá numerická data jako Little-endian, tak jiná jako Big-endian :-(
Procesor Pentium a jeho struktura
Terminologie
Při popisu procesorů řady Intel bývá zvykem používat kromě shora uvedených termínů bit a byte následující: slabika (=byte), slovo (= 2 byty, angl. Word), dvojslovo (=4 byty, angl. Doubleword) a čtyřslovo (= 8 bytů, angl. Quadword). Často se také pro vyloučení pochybností uvádí i počet bitů - např. 16bitové slovo.
- Slovo je tvořeno 2 byty = 16 bity. Ty jsou číslovány od 0 do 15 (viz výše), přičemž bity 0 až 7 tvoří dolní slabiku, bity 8 až 15 tvoří horní slabiku. V paměti jsou uloženy jako Little Endian, tj. dolní slabika je uložena na nižší adrese a ta je adresou celého slova.
- Dvojslovo je tvořeno 4 byty = 32 bity. Ty jsou číslovány od 0 do 31, přičemž bity 0 až 15 tvoří dolní slovo, bity 16 až 31 tvoří horní slovo. V paměti jsou uloženy jako Little Endian, tj. dolní slabika dolního slova je uložena na nejnižší adrese a ta je adresou celého dvojslova.
- Čtyřslovo je tvořeno 8 byty = 64 bity. Ty jsou číslovány od 0 do 63. V paměti jsou uloženy jako Little Endian analogicky předchozím datových strukturám.
Organizace paměti
Paměť připojená na sběrnici procesoru se nazývá fyzická paměť. Je organizována jako posloupnost slabik. Každé slabice je přiřazena fyzická adresa, která je v intervalu 0 až 232 - 1 (= 4 GB).
Technické prostředky správy paměti odstiňují programátora od fyzických adres a poskytují mu tzv. virtuální paměť. Správa paměti dává programátorovi k dispozici segmentování a stránkování paměti. Segmentování paměti je mechanismus poskytující násobný a nezávislý přístup k adresovému prostoru. Stránkování paměti podporuje vytváření rozsáhlejšího adresového prostoru, než je dostupná kapacita fyzické paměti s použitím vnější diskové paměti. Mechanismy se mohou používat oba, nebo jenom některý z nich.
Odkazuje-li se program na paměť, použije tzv. logickou adresu. Ta se segmentováním překládá na nesegmentovou tzv. lineární adresu. Stránkování může lineární adresu dále přeložit na fyzickou adresu. Není-li stránkování zapnuto, je fyzická adresa totožná s lineární.
Paměť můžeme používat buď jako nestrukturovaný adresový prostor, podobně jako bychom přímo používali fyzické adresy, nebo lze paměť rozdělit do vzájemně nezávislých prostorů nazývaných segmenty. Různé segmenty se vytvářejí pro uložení instrukcí prováděného programu, pro jejich data nebo zásobník. Jeden proces může mít až 16 383 segmentů různých velikostí a typů. Jeden z důležitých významů existence segmentů je zvýšení spolehlivosti operačního systému. Např. zásobníky se umísťují do speciálních segmentů. V případě, že by do zásobníku bylo uloženo více položek, než je kapacita segmentu, detekuje se pokus o překročení hranic segmentu a nemůže tedy dojít k přepisu instrukcí nebo dat jiného nebo i vlastního procesu.
Logická adresa se skládá ze dvou složek, ze selektoru a offsetu. Selektor ukazuje na jeden z popisovačů v některé tabulce. Popisovač mj. obsahuje bázi (adresu začátku) segmentu a limit (velikost) segmentu. Offset je potom relativní adresa uvnitř segmentu (počítá se od začátku segmentu). Offset nesmí překročit limit. Logickou adresu, ve které se jednotlivé složky (tj. selektor a offset) oddělují dvojtečkou, zapisujeme ve tvaru:
selektor : offset
Stránkováním, je-li zapnuto, se lineární adresa rozděluje na stránky stejné velikosti.
Stránka může potom být buď v paměti, nebo na disku. Paměť je totiž stránkováním rozdělena na rámce stejné velikosti jako stránky. Rámce potom operační systém „pronajímá“ stránkám, které jsou v daném okamžiku potřebné. Momentálně nepotřebné stránky se odkládají na disk. Odpovídající adresaci potom zajistí právě mechanismus stránkování. Není-li potřebná stránka v některém z rámců, generuje procesor tzv. výjimku, čímž se předá řízení programové rutině zajišťující přenos potřebné stránky do paměti.
Registry
Činnost procesoru při vykonávání jednotlivých instrukcí se opírá o soustavu interních paměťových míst nazývaných registry. Právě prováděná instrukce většinou předpokládá - podle svého určení - v přesně definovaných registrech hodnoty přesně definovaného významu. Při svém provádění může hodnoty definovaných registrů měnit na (o) definovanou hodnotu a po svém ukončení může zanechat definované registry nastavené na definovanou hodnotu.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
Programátorovi přístupné registry
Adresace
Pevně stanovené registry mají základní význam pro určení té adresy paměti, se kterou pracuje právě prováděná instrukce. Způsob výpočtu tzv. efektivní adresy určuje následující schéma:
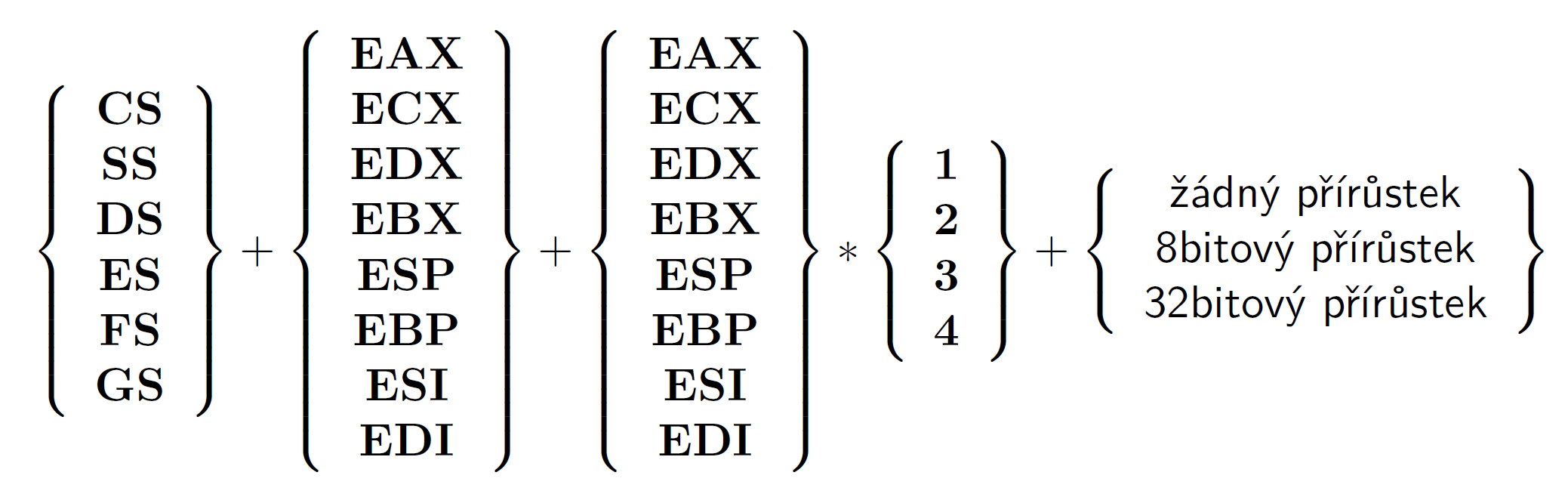
Kompletní tvar pro výpočet efektivní adresy
Interpretace dat procesorem
Datové struktury uvedené výše jsou při provádění instrukcí procesorem interpretovány různými instrukcemi různě.
- Celé číslo se znaménkem (Integer): celé číslo se znaménkem je hodnota ve dvojkovém doplňkovém kódu v 32bitovém dvojslově, 16bitovém slově nebo 8bitové slabice. Znaménkový bit je bitem nejvyššího řádu. Pro záporné číslo má hodnotu 1, nulový je pro čísla kladná a nulu. Rozsah zobrazení pro slabiku je -128 až 127. Pro slovo -32 768 až 32 767. Pro dvojslovo je -231 až 231 -1.
- Celé číslo bez znaménka (Ordinal): celé číslo bez znaménka bývá uloženo ve dvojslově, slově nebo slabice. Rozsah zobrazení pro slabiku je 0 až 255, pro slovo 0 až 65 535 a pro dvojslovo 0 až 232 - 1. Typ se také označuje jako neznaménkové celé číslo (Unsigned Integer).
- Dvojkově kódovaná desítková celá čísla (BCD Integer – Binary Coded Decimal Integer): v kódu dvojkově kódovaných desítkových číslic (zkráceně označován BCD) je jedna desítková číslice (0 až 9) uložena ve 4 bitech.
- Blízký ukazatel (Near Pointer): je to efektivní adresa. Je tvořena offsetem v rámci segmentu.
- Vzdálený ukazatel (Far Pointer): je to logická adresa složená ze segmentu a offsetu.
- Bitové pole (Bit Field): je to posloupnost bitů. Může začínat na libovolné pozici libovolné slabiky a může být dlouhá až 32 bitů.
- Bitový řetězec (Bit String): je to posloupnost bitů délky až 232 - 1 bitů začínající na libovolné pozici libovolné slabiky.
- Řetězec slabik (Byte String): je posloupnost slabik (i slov nebo dvojslov). Řetězec může začínat na libovolné slabice může být dlouhý až 232 - 1 slabik (4 GB).
- Číslo v pohyblivé řádové čárce (Floating-Point): používá jej jednotka operací v pohyblivé řádové čárce (FPU).
Assembler
Program ve strojovém kódu
Základním úkolem programátora je vytváření spustitelných aplikací - tj. posloupnosti instrukcí, jejichž provedením realizuje procesor algoritmus zamýšlený programátorem (tedy většinou :-). V převažujícím počtu případů vytváří programátor spustitelné aplikace řetězem činností, kde na počátku stojí text programu v nějakém vyšším programovacím jazyce a na konci posloupnost nul a jedniček tvořících množinu instrukcí vykonatelných procesorem. Je pravdou, že ty nuly a jedničky může programátor za přispění dlouhého seznamu jednotlivých instrukcí popisujících jejich dvojkové kódování zapsat přímo. Avšak tito programátoři se po jisté době - delší nebo spíše kratší - přemísťují do městských čtvrtí Bohnice v Praze, Kateřinky v Opavě a jim podobných (asi aby pro svou práci měli dostatečný klid).
Nicméně ve výjimečných případech je buď nanejvýš vhodné nebo přímo nutné skutečně vytvořit část programu na úrovni strojových instrukcí. Přitom je programátor stresován dvěma skutečnostmi:
- Především neustálým nahlížením do seznamu strojových instrukcí za účelem nalezení dvojkového kódování.
- Dále starostí o přidělování adres těm paměťovým prostorům, které hodlá využít pro data svého programu.
Naštěstí obě skutečnosti lze (za přispění pomocného programu) automatizovat. Místo dvojkového kódu instrukcí (které si snad nikdo normálně nedovede zapamatovat) zapisuje programátor do běžného textového souboru mnemotechnické zkratky instrukcí, které lze zapamatovat snáze (např. ADD - sečti, JNZ - Jump if Not Zero - skoč při nenulovém výsledku apod.). Místo konkrétní dvojkové adresy svých dat zapisuje (opět mnemotechnicky zvolené) označení - např. podle významu, který konkrétní data v jeho algoritmu mají.
Zmíněný pomocný program pak čistě mechanicky vyhledá ke mnemotechnickému zápisu instrukce (třeba ADD) příslušný binární kód (zde třeba 0000 0I0I), mnemotechnickému označení dat přidělí volnou adresu paměti. Získané binární kódy instrukcí, do binárního tvary převedené adresy dat a další náležitosti podle požadavku operačního systému zapíše do souboru v konvencích tohoto operačního systému - u MS např. do souboru s příponou „exe“ - a to je ta kýžená spustitelná aplikace.
Takový pomocný program, který převádí mnemotechnicky textově zapsané instrukce a mnemotechnicky označené adresy dat na spustitelné aplikace, bývá označován jako assembler (to assembly = sestavit, zde ve smyslu sestavení spustitelné aplikace). Potažmo programátor, píše-li textový soubor jako vstup takového sestavovacího programu, „programuje v assembleru“, tedy na nejnižší možné úrovni, na úrovni strojových instrukcí.
Příklad programu, který na systémové konzole zobrazí text Nazdar! psaný v assembleru (mov ~ move, přesun; int ~ interrupt, vyvolání přerušení):
; POZDRAV.ASM - Zobrazí pozdrav
; Addr Hexa-content Label Instr Comment
; ----------------------------------------------------------------------------------
0000 .MODEL small
0000 .STACK 100h
0000 .DATA
0000 4E 61 7A 64+ TX DB 'Nazdar!$'
61 72 21 24
0008 .CODE
0000 B8 0000s mov ax, @data ; Do AX pointer na Data Segment
0003 8E D8 mov ds,ax ; DS := AX (není tvar DS := pointer)
0005 B4 09 mov ah,9 ; Číslo DOS funkce: zobrazení
0007 BA 0000r mov dx,OFFSET TX ; Do DX pointer na zobrazovaný text
000A CD 21 int 21h ; Volání funkce DOSu s číslem v AH
000C B4 4C mov ah,4ch ; Číslo DOS funkce: ukončení programu
000E CD 21 int 21h ; Volání funkce DOSu s číslem v AH
END
Jazyky a překladače
Výše uvedený příklad může být zajímavý, ale rozhodně není samoúčelný. Uvažujme následující úlohu: Do bytu s adresou třeba 20 potřebujeme dostat číslo z adresy třeba 27 zvětšené o hodnotu z adresy 31. Schematicky:
mov ah, [27] add ah, [31] mov [20], ah
Toto jsou instrukce, které procesor umí přímo vykonat. Ovšem ne každý programátor je dovede vytvořit a rozumně přitom hospodařit s pamětí. Je třeba si uvědomit, že kdykoliv je zapotřebí sečíst dvě čísla a součet umístit na nějaké místo v paměti (třeba Novákovi zvětšit plat o 300,- nebo odvěsnu B nastavit o 2 jednotky větší než je odvěsna A), pak procesor musí vždy vykonat uvedené tři instrukce; budou se lišit pouze adresami v paměti:
mov ah, [PlatNov] add ah, [Priplatek] mov [PlatNov], ah
nebo
mov ah, [OdvesnaA] add ah, [Zvetseni] mov [OdvesnaB], ah
Z hlediska hospodaření s pamětí to vyřeší už assembler. Zbývají - byť mnemotechnické - instrukce procesoru. Kdyby se nám podařilo vytvořit program (pravda, o trochu složitější než assembler), který by četl také (jako assembler) nějak formalizovaný text obsahující popis činností a dat, a generoval příslušné instrukce procesoru s příslušnými adresami - jó, to už by bylo jiná:
PlatNov ← PlatNov + Priplatek OdvesnaB ← OdvesnaA + Zvetseni
V obou případech logicky musí být generovány stejné instrukce uvedené v assemblerských příkladech shora, samozřejmě s různými adresami. A to je princip tzv. vyšších programovacích jazyků.
Velmi zhruba: Vyšší programovací jazyk je soustava pravidel, kterak (textově!) vytvářet které konstrukce, a jakou funkci jednotlivé konstrukce mají při provádění (už generovaných) strojových instrukcí. Pravidla pro zápis bývají označovány jako syntaxe programovacího jazyka a význam jednotlivých jeho konstrukcí jako sémantika.
Program, který čte text vytvořený dle pravidel (syntaxe) jazyka J a na jeho základě generuje instrukce proveditelné procesorem P, vlastně převádí text z jednoho jazyka J do jiného jazyka - jazyka instrukcí procesoru P. Proces převodu z jednoho jazyka se obvykle nazývá překlad a na rozdíl od člověka - překladatele se programy takovou činnost provádějící nazývají překladače (compilers).
Ona dvojice J - P zmíněná v předchozím odstavci je určující pro použitelnost celého procesu vytváření spustitelné aplikace. Mohu být jednička v programování v Cobolu na svém starém dobrém PC s Intelem, ale na Samsungu s Androidem jsem nula, protože tam není překladač z Cobolu do instrukční sítě procesoru Snapdragon. I na svém PC jsem nula, pokud sice perfektně, ale pouze ovládám Algol68 - protože pro něj nikdo nevytvořil překladač do instrukcí Intelu.
Interpret
Kromě překladače z jazyka J do „čistého“ kódu procesoru (a tedy vytvoření kdykoliv odkudkoliv spustitelné aplikace) však existuje ještě jedna logika použití textu programu ve vyšším jazyku. Program - nazývaný tentokrát nikoliv překladač, ale interpret - pracuje následovně:
- Přečte z textového vstupu jistý logický element, pro představu nejčastěji jeden příkaz.
- Tento element rozebere z hlediska sémantiky (významu) a nechá procesor vykonat ty činnosti, které danému významu odpovídají.
- Přečte z textového vstupu další element, ten opět rozebere a nechá vykonat ... atd.
Toto byl jen popis na té nejjednodušší myslitelné úrovni. Ve skutečnosti autoři programů - interpretů mohou volit daleko mnohotvárnější přístupy k interpretaci textu programu ve vyšším jazyku. Mohou např. každý načtený element interně skutečně přeložit do instrukcí procesoru (do nějaké dočasně přidělené oblasti paměti), nechat instrukce vykonat a pak onu dočasnou oblast uvolnit. Mohou načtený element (nebo i celý text) „předkompilovat“ do sekvencí nějakého svého kódování (tzv. mezikódu), a pak tyto sekvence jednu po druhé předkládat jako parametry svých účelově vytvořených podprogramů. V naprosté většině autoři interpretů o podrobnějším popisu funkce pochopitelně zarytě mlčí, protože to je to jejich „know how“.
Společným rysem interpretů je to, že nevzniká soubor s instrukcemi procesoru, který je pak možno bez dalších činností procesoru přímo předkládat k vykonání. Při každém dalším požadavku na provedení algoritmu (= spuštění programu ve vyšším jazyku) je třeba vždy znovu a znovu nechat vykonávat shora popsanou posloupnost činností. Nejenom to: pokud program obsahuje cyklus, pak se vždy znovu a znovu, při každém průchodu cyklem, vykonává rozbor a interpretace těla cyklu. Je evidentní, že vykonání nějakého mého programu ve vyšším programovacím jazyku interpretem je mnohonásobně pomalejší než vykonání téhož programu přeloženého překladačem do kódu stroje.
Poznámka: Je to sice pomalejší, ale u relativně ne příliš složitých programů na dnešních výkonných strojích - upřímně: má-li to trvat místo miliontiny vteřiny celou tisícinu vteřiny, vadí nám to moc?
Rozdíl mezi použitím interpretu a překladače mohou dokreslit následující schémata:
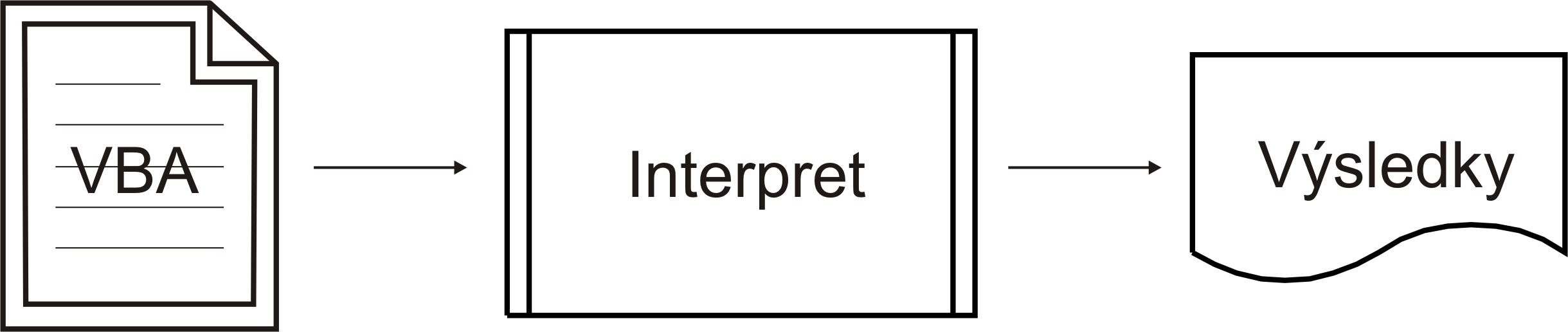

Velmi známým příkladem interpretovaného jazyka je Sun Java, který od počátku byl budován jako interpretovaný (zvláště pro účely Java scriptu v HTML souborech), teprve později na některých platformách přibyly překladače.
Prostředí Microsoftu byla k roku 2006 doplněna o rozšíření definice jazyka Basic 6 (pak označované jako VBA - Visual Basic for Applications) a byl vytvořen interpret tohoto jazyka ve formě virtuálního stroje. Dalším počinem Microsoftu bylo uvolnění samostatné aplikace, kterou může spustit víceméně kterýkoliv jiný běžící program jakožto svého „hosta“. Tato aplikace obsahuje kompletní vývojářské prostředí (IDE), ve kterém lze připravit text programu a uchovat ho v hostitelském programu, předkompilovat text programu do mezikódu (též pseudokódu) a předložit ho virtuálnímu stroji k vykonání. Zmíněná aplikace je dostupná z hostitelských programů většinou jako Visual Basic Editor (VBE).
Literatura a další doporučené zdroje
[1] BRANDEJS, M.: Mikroprocesory Intel Pentium [online]. Fakulta informatiky, Masarykova univerzita, Brno. 2010. [cit. 2.1.2021]. Dostupné z: https://www.fi.muni.cz/usr/brandejs/Brandejs_Mikroprocesory_Intel_Pentium_2010.pdf
[3] Informatika. In: Wikipedie: Otevřená encyklopedie [online]. Wikimedia Foundation, 2003. [cit. 4.6.2017]. Dostupné z: https://cs.wikipedia.org/wiki/Informatika
[4] Endianness in: TANNENBAUM, A. S., AUSTIN, T.: Structured Computer Organization. 6th edition. Boston: Pearson, 2013. ISBN 9780132916523.
[5] International System of Units (SI): Prefixes for binary multiples. National Institute of Science and Technology. [cit. 4.10.2017]. Dostupné z: https://physics.nist.gov/cuu/Units/binary.html
[6] GOLDBERG, D.: What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys. March 1991. p: 5–48. doi: 10.1145/103162.103163.
[6] Institute of Electrical and Electronics Engineers: IEEE Standard 754-1985 for Binary Floating-Point Arithmetic, IEEE 1987. Reprinted in SIGPLAN 22, 2, 9-25.